
|
Match Editorial |
Thursday, October 4, 2007
Match summary
Competitors faced tricky problem sets in SRM 369, which ended up being unrated due to some unfortunate technical issues.
In division 1, seven coders submitted the hard problem including six who submitted all three. However, Petr was the only person to successfully solve all three problems,
with Vasyl[alphacom] and pashka rounding out the top 3. The easy problem, which was also division 2's medium problem, was very tricky,
and required careful thinking in order to avoid many pitfalls. The medium problem also had a fairly low success rate, and required some mathematical observations. The challenge phase was very active,
and included an excellent performance by gevak, who netted 500 points and 11 successful challenges.
In division 2, coders were faced with a straitforward easy problem followed by an unusually tricky medium problem as well as a hard problem that was fairly difficult conceptually.
Only one coder, woodfish6178, solved the hard problem and won the match. Rounding out the top 3 were Vovako and easel.
The Problems
ChainOfRectangles

Used as: Division Two - Level One:
Value 250 Submission Rate 569 / 632 (90.03%) Success Rate 493 / 569 (86.64%) High Score narri for 246.51 points (3 mins 23 secs) Average Score 187.25 (for 493 correct submissions)
The fact that we aren't given the exact locations of the rectangles gives us a hint on how to solve this problem. Imagine that several rectangles have already been placed,
and that we know the total area covered by the three colors. When we place the next rectangle with area W inside the previous one, then the area covered by the color of
the previous rectangle will decrease by W, while the area covered by the color of the next rectangle will increase by W. Note that this still works if we place a rectangle
inside another rectangle of the same color.
The solution then is to iterate through each rectangle while keeping track of the color of the last placed rectangle. As we process each rectangle, we update the amount of area
that each color covers. Finally, we check which color covers the most area, and return that area. Sample C++ code follows:
int ChainOfRectangles::getMaximalArea(vectorBeautifulStringwidth, vector height, string color) { vector ret(3); int last=-1; for(int i=0;i<width.size();i++) { int a=width[i]*height[i], c=0; if(color[i]=='G') c=1; if(color[i]=='B') c=2; if(last!=-1) ret[last]-=a; ret[c]+=a; last=c; } return max(ret[0],max(ret[1],ret[2])); }
Used as: Division Two - Level Two:
Used as: Division One - Level One:
Value 500 Submission Rate 406 / 632 (64.24%) Success Rate 48 / 406 (11.82%) High Score rejudge for 419.62 points (12 mins 57 secs) Average Score 290.31 (for 48 correct submissions)
Value 250 Submission Rate 552 / 585 (94.36%) Success Rate 210 / 552 (38.04%) High Score Rhubarb for 248.66 points (2 mins 5 secs) Average Score 174.30 (for 210 correct submissions)
This problem is most easily solved by carefully examining several cases.
- Case 1: maxA=0 or countA=0 We must restrict ourselves to only using 'B' letters, so the answer is min(maxB,countB). Note that this also covers the case where we can't use any letters.
- Case 2: maxB=0 or countB=0 This case is similar to case 1, except we restrict ourselves to using 'A' letters, so the answer is min(maxA,countA).
- Case 3: There aren't enough 'B' letters to use the maximum number of 'A' letters Each group of 'A's must contain exactly maxA letters, otherwise we could add another group and thus more 'A' letters. Thus, we can check for this case by testing if Since each group of 'A's must be seperated by at least one 'B', we can use at most (countB+1)*maxA 'A' letters, and we can use all of our 'B' letters by dispersing them through various 'A' groups.
- Case 4: There aren't enough 'A' letters to use the maximum number of 'B' letters This case is similar to the one above. We can use at most (countA+1)*maxB 'B' letters and all of our 'A' letters.
- Case 5: None of the above As none of the above cases apply, then we aren't restricted in our ability to use our 'A' or 'B' letters, so the answer is countA+countB.
Used as: Division Two - Level Three:
Value 1000 Submission Rate 12 / 632 (1.90%) Success Rate 1 / 12 (8.33%) High Score woodfish6178 for 457.83 points (43 mins 57 secs) Average Score 457.83 (for 1 correct submission)
Consider the regular octagon P below. Let f(P,k) denote the number of triangulations of P that contain exactly k isosceles triangles.
Clearly the edge connecting vertices 0 and 7 must be part of some triangle in the triangulation of the octagon.
So consider all possible ways of choosing a third vertex to complete this triangle. Notice what happens if we choose vertex 3. The triangle that is formed
partitions the polygon into two disjoint smaller polygons. If we could figure out how many isosceles triangles belong to sub-polygon A (call this number m), then we
know that sub-polygon B must contain exactly k-m isoceles triangles. Therefore, the number of ways to construct a k-isosceles triangulation such that triangle (0, 3, 7)
is included in the triangulation is the summation of f(A,m)*f(B,k-m), for all possible 0≤m≤k.
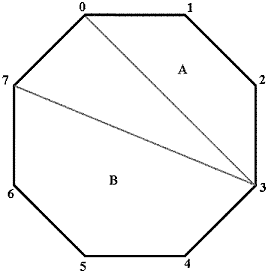
These observations lead to a rather straitforward dynamic programming algorithm. Each state is composed of a sub-polygon of the original, as well as an integer denoting how many isosceles triangles
must belong to the polygon. As illustrated above, our "starting edge" for the entire polygon was edge (0, 7). After splitting the polygon into parts A and B, you can use edge (0, 3) as the starting edge
for polygon A, and edge (3, 7) for the starting edge of polygon B. Thus, we can represent each sub-polygon as a pair of integers, representing the first and last vertices contained in the polygon, in
clockwise order. To compute f(P,k) for a given polygon, we try each possible vertex that can complete a triangle which includes the "starting edge" of p. For each of these vertices, we try
every valid way of assigning the number of isosceles triangles to each resulting sub-polygon. We must also remember to subtract one from k whenever our constructed triangle for a given
starting edge and third vertex is isosceles itself.
There are two base cases. One base case is a triangle, in which case f(P,k)=1 if k=1, and 0 otherwise. The other base case is the "empty" polygon consisting of only an edge.
Here, f(P,k)=1 if k=0, and 0 otherwise. An implementation of this algorithm in C++ follows:
int dist[51][51];
long long dp[51][51][51];
bool iso(int a, int b, int c) {
if(a>b) swap(a,b);
if(a>c) swap(a,c);
if(b>c) swap(b,c);
return a==b||b==c;
}
long long solve(int start, int end, int k) {
if(k<0) return 0;
if(start+1==end) return k==0;
if(start+2==end) return k==1;
long long &ret=dp[start][end][k];
if(ret!=-1) return ret;
ret=0;
for(int i=start+1;i<=end-1;i++) {
int a=dist[start][i], b=dist[i][end], c=dist[start][end];
int isoc=iso(a,b,c);
for(int kk=0;kk<=k-isoc;kk++) ret=(ret+solve(start,i,kk)*solve(i,end,k-isoc-kk))%123456789;
}
return ret;
}
int IsoscelesTriangulations::getCount(int n, int k) {
for(int i=0;i<n;i++) for(int j=i+1;j<n;j++) dist[i][j]=min(j-i,i+n-j);
memset(dp,-1,sizeof(dp));
return solve(0,n-1,k);
}
AbsSequence
Used as: Division One - Level Two:
Value 500 Submission Rate 237 / 585 (40.51%) Success Rate 55 / 237 (23.21%) High Score ahyangyi for 391.41 points (15 mins 54 secs) Average Score 255.08 (for 55 correct submissions)
We clearly can't generate the entire sequence, as this approach will easily timeout. Instead, let's play around with the sequence and see if any patterns emerge. Consider the sequence generated
by first=9 and second=7, which is (9, 7, 2, 5, 3, 2, 1, 1, 0, 1, 1, 0, ...). One interesting observation is that the sequence is periodic at the end. Moreover, the nonzero repeating digit is 1, which is the
greatest common divisor of 9 and 7. There is a more interesting pattern here, however. Let x=first, y=second, and d=x-y, and look at the first 7 numbers in the sequence. Here, we have that this subsequence is
(x, x-d, d, x-2d, x-3d, d, x-4d). Notice that after x-4d, x-5d is not in the sequence, as 5d>x. We can further observe that this pattern can be generalized to any two starting values.
So as long as x>y, we know what the first several elements in our sequence look like.
But what happens when we need to generate the elements after this pattern starts to fail? We can simply take the last two elements of the subsequence where the pattern holds and begin computing a
new subsequence! In order for this information to be useful, we need an upper bound on the number of subsequences (that is, subsequences that obey our observed pattern) that we will need to look at. Notice that either the last or next-to-last
element in a given subsequence is x-a*d, where a is the largest positive integer such that a*d≤x, which is equivalent to x%d. Let's fix where our subsequence ends, such that the last
element will always be d. Then the next-to-last element must be either x%d or x%d+d. If the next-to-last element is x%d, then our next subsequence will start with the pair (d,x%d). Otherwise,
the next subsequence will begin with the pair(d,x%d+d). This shows us that the number of subsequences we must consider is roughly the same as the number of recursions needed to compute euclid's GCD algorithm, which grows logarithmically.
Armed with this knowledge, we can finally create a fast solution. Let us define a recursive function F(x,y,n) which denotes the nth element of the sequence generated by taking x and y as
the first two values. There are several cases to consider.
- Case 1: n<2 The answer for this case is clearly either x or y.
- Case 2: y=0 The rest of the sequence will look like (x, 0, x, 0, ...), so the answer is 0 if idx is odd, and x otherwise.
- Case 3: x≤y Our observations above only held if x>y, but since x≤y implies that y-x=0 or y-x<y, we can just return F(y,y-x,n-1), since this case never happens twice in a row.
- Case 4: x>y This is the primary case. To simplify implementation matters, we observe that the subsequence (x, x-d, d, x-2d, x-3d, d, x-4d, ...) can be viewed as blocks of 3 elements (namely those ending with 'd'). Therefore, we want to find the maximum number of three-element blocks such that x≥a*d, for each x-a*d term in our subsequence. Assume that b is the largest coefficient of d such that x-b*d that appears in the subsequence. There are two cases to consider here:
- Case A: If n+1 is less than or equal to the number of elements in our blocks, then we know that the nth element of the sequence lies in these blocks. Looking back to our pattern, we can tell that if n%3=2, then F(x,y,n)=d. Otherwise, the answer will be in the form x-c*d, for some positive integer c. As there must be (n+1)/3 'd' occurences before the nth element of the subsequence, we have that c=n-(n+1)/3. Thus F(x,y,n)=x-d*(n-(n+1)/3).
- Case B: If n+1 is greater than the number of elements in our blocks, then the nth element of the sequence must occur in the next subsequence. Here, F(x,y,n)=F(x-d*b, d, n-len+1), where len is the total length of our subsequence.
long long solve(long long x, long long y, long long idx) {
if(idx==0) return x;
if(idx==1) return y;
if(y==0) return (idx%3==1)?0:x;
if(x<=y) return solve(y,y-x,idx-1);
long long diff=x-y;
long long block=x/diff;
if(block%2==0) block--;
long long len=block+(block+1)/2;
if(idx>len-1) return solve(x-diff*block,diff,idx-len+1);
else {
if(idx%3==2) return diff;
else return x-diff*(idx-(idx+1)/3);
}
}
MountainMap
Used as: Division One - Level Three:
Value 1000 Submission Rate 7 / 585 (1.20%) Success Rate 1 / 7 (14.29%) High Score Petr for 468.48 points (42 mins 8 secs) Average Score 468.48 (for 1 correct submission)
First, let's assume we can solve the easier problem of computing the number of maps such that the 'X' cells are locally minimal, and the other cells may or may not be locally minimal.
How can we use this to solve the original problem? It's crucial to realize that the maps counted by this easier problem is a superset of the maps that we must count for
our original problem. Therefore, it suffices to compute how many maps are counted in this easier problem and subtract off all of the maps that violate
the constraint that the '.' cells must not be locally minimal.
How do we compute these maps? We simply try each combination of adding extra 'X' cells to the map, and solve the easier problem for each new map.
However, if we just subtract the number of maps counted by each of these new problems, then we end up subtracting off some maps several times. Why? Well, assume
that we subtract off the number of maps generated by the easier problem generated by adding one extra 'X' cell. Then we end up subtracting off
many maps that may have more cells that are locally minimal than the 'X' cells that we started off with. These maps will be subtracted off again
when we actually consider problems that add 'X' marks in these cells.
So what we need to use is the principal of inclusion-exclusion. For each combination of adding (possibly zero) 'X' cells to the grid, we subtract
the number of maps counted by the easier problem if the number of 'X' cells we added is odd, and subtract the number of maps otherwise.
Of course, we still haven't solved the easier problem yet. First, notice that if the grid has two adjacent 'X' cells, then there can be no valid maps.
There can also be no valid maps if no 'X' cell is present. To solve our problem, we can realize that if we fill in the heights in increasing order, then
no 'X' cell may be assigned a height after any of its neighbors. Let us create a dynamic programming algorithm where the state is the pair (k,mask), where
k is the height that we will assign next (this assumes that heights 0 through k-1 have already been assigned), and mask is a bitmask corresponding to which
'X' cells have been assigned a height. Assume that the number of 'X' cells that have been assigned is b. Then the number of '.' cells that have been assigned
is k-b. So if we have a total of m '.' cells that have no neighboring 'X' cells that haven't been assigned, then there are a total of m-(k-b) '.' cells that
may be assigned height k. Of course, any unassigned 'X' cell can be assigned height k.
Assume f(k,mask) denotes the number of maps that have heights 0 through k-1 assigned that have assigned heights to the set of 'X' cells represented by mask.
Clearly, if k=n (where n is the number of cells in the grid), then f(k,mask)=1. Otherwise, we can add to our return value f(k+1,mask UNION i), for each
unassigned 'X' cell i. Also, if m is the number of '.' cells that have no neighboring 'X' cells that haven't been assigned and b is the number of assigned 'X' cells,
we add (m-(k-b))*f(k+1,mask) to our return value. These additions completely compute f(k,mask).
We must be careful with implementing this algorithm, as a nieve implementation may be too slow. One helpful observation is that each cell may have at most 4 neighboring 'X' cells.
So precomputing the 'X'-neighbors for each cell can roughly cut our execution time in half. Additionally, we can keep a bitmask corresponding to which cells in the grid
are 'X' cells combined with an array that tells us how many 'X' cells lies before a specific cell.
You can view Petr's solution for a bottom-up DP implementation of this algorithm.
