
|
Match Editorial |
Monday, September 18, 2006
Match summary
SRM 319 was the first SRM hosted by TopCoder in nearly three weeks - and it was a money SRM to boot! As if coders needed more incentive, this was the last SRM before TCCC round 1 and GCJ round 2 to practice those skills. These reasons were enough to attract the second largest crowd ever for a TopCoder SRM, with 1001 coders taking part in the match. This was only the second SRM in TC history with more than 1000 participants, behind SRM 294.
In division 1, coders were faced with a relatively easy set overall, with many contestants solving all three problems. Although reid was in the lead after the coding phase, kalinov took top spot in Division 1 thanks to two successful challenges. Rounding out the top five were ardiankp, ploh and Gassa.
In division 2, the hard problem seemed to trip up several coders. Nonetheless, the top five of windbells, toshitoshi, SilverKnight, diegoalvarez and Barty_ each had scores of over 1200 points, with positions 2, 3 and 5 being occupied by newcomers to TC.
The Problems
SkewSymmetric

Used as: Division Two - Level One:
Value 250 Submission Rate 386 / 492 (78.46%) Success Rate 340 / 386 (88.08%) High Score cluster2006 for 247.67 points (2 mins 45 secs) Average Score 183.56 (for 340 correct submissions)
In this problem, coders were asked to determine the minimum number of alterations required to transform a given matrix into a skew-symmetric matrix.
The easiest way to solve this problem is to note that values in the original matrix at position row i, column j map to position row j, column i under the transposition operation. In this way, we form pairs of values - denoted by x and y - that will map to each other under transposition. Now, for every pair where x does not equal -y, we can simply choose to alter either one of x or y. Note that values on the diagonal of the matrix map to themselves under transposition. Thus, we are looking for values of x such that x = -x. Only the value 0 satisfies this constraint, so we arrive at the condition that the diagonal values must be 0 in a skew-symmetric matrix. Pseudocode to solve the entire problem follows:
// Given M, an N by N matrix
numAlterations = 0
// Diagonal must be all 0
for i:0 to N-1
if M[i][i] != 0 numAlterations++
// Check only one half of matrix
for i:0 to N-1
for j:i+1 to N-1
if M[i][j] != -M[j][i] numAlterations++
return numAlterations
BusSeating
Used as: Division Two - Level Two:
Used as: Division One - Level One:
Value 500 Submission Rate 276 / 492 (56.10%) Success Rate 239 / 276 (86.59%) High Score mythruby for 473.86 points (6 mins 44 secs) Average Score 335.29 (for 239 correct submissions)
Value 250 Submission Rate 436 / 450 (96.89%) Success Rate 417 / 436 (95.64%) High Score ihi for 246.35 points (3 mins 28 secs) Average Score 211.16 (for 417 correct submissions)
The situation presented in this problem comes up often in the real-world. Of course, in the real-world, the group of friends is more likely to just stand on the bus to be closer together... Here, however, we were asked to minimize the sum of distances between each pair of friends.
This problem was not very difficult, with the toughest task being to translate the words from the statement into a working model. The most straightforward model for the seats on the bus is to represent them as points in the Cartesian plane. In particular, we can model the left row of seats as lying along the positive y-axis, where the origin of the coordinate system represents the front of the bus. Then, the points (0,0), (0,1), (0,2), ... , (0,9) represent the seats in the left row. Next, the seats in the right row can be represented using the points (2,0), (2,1), (2,2), ... , (2,9). Note that the positioning of these points takes into account the specified separation between seats given in the problem statement.
Once those preliminaries are out of the way, the problem reduces to simply finding 3 of those points - p1, p2 and p3 - such that the sum d(p1,p2) + d(p1,p3) + d(p2,p3), where d(x,y) represents the Euclidean distance between the points x and y, is minimized. Note that the distinction between left and right row is irrelevant once the coordinates have been setup as above. For this reason, the two input strings may be concatenated and treated as one long input string. Pseudocode to solve this problem follows:
// px, py represent the x and y coordinates as described above
function dist(a,b)
return sqrt( (px[a]-px[b])*(px[a]-px[b]) + (py[a]-py[b])*(py[a]-py[b]) )
function getArrangement(leftRow, rightRow)
full = leftRow + rightRow
minDist = INF
for i:0 to 19
for j:0 to 19
for k:0 to 19
if full[i] != 'X' and full[j] != 'X' and full[k] != 'X'
if dist(i,j) + dist(j,k) + dist(i,k) < minDist
update minDist
return minDist
IncompleteBST
Used as: Division Two - Level Three:
Value 1000 Submission Rate 63 / 492 (12.80%) Success Rate 9 / 63 (14.29%) High Score Barty_ for 905.46 points (9 mins 22 secs) Average Score 589.52 (for 9 correct submissions)
In this problem, coders had to work with a fairly common data structure in CS, a binary tree. To be more specific, coders were given a binary search tree (BST) with one unknown node value, and were asked to determine the possible values that the node may assume while still maintaining a valid BST. Although the solution to this problem isn't overly complicated, division 2 coders rarely have to work with binary trees, and this may have presented some challenges.
The first sub-challenge in this problem was to figure out the relationship between nodes under the given numbering scheme. In fact, if a given node is numbered x, then the node's left-child will be numbered 2*x and the right-child will be numbered 2*x+1. As for representing the tree itself, a simple hash map may be used, using the node identifiers as keys to map to the node values.
Once we have the tree setup as above, and we have identified the index of the unknown value, the most obvious way to approach this problem is to try all possible values (in the range 'A'-'Z') as the unknown value and verify that the resulting tree is still a valid BST. The key function here is one which determines whether a given tree constitues a valid BST. The pseudocode for this function is given below, followed by a brief explanation:
// myTree is the map (node identifier maps to node value)
function isValidBST(curNode, minChar, maxChar)
// the value of the current node is not within allowed character range
if myTree[curNode] < minChar or myTree[curNode] > maxChar
return false
return
// recursively check that left subtree is valid
isValidBST(2*curNode, minChar, myTree[curNode])
and
// recursively check that right subtree is valid
isValidBST(2*curNode+1, nextCharacter(myTree[curNode]), maxChar)
The above function should be called initially as `isValidBST(1, 'A', 'Z')'. The function verifies that the value of curNode lies within the character range [minChar - maxChar] inclusive. Thus, a call of `isValidBST(1, 'A', 'Z')' indicates that the value of the root node of the BST can lie anywhere in the range ['A'-'Z']. The function then recursively verifies the validity of the left and right subtrees. Note how the range within which node values may lie is updated in the recursive call to the function. Since the left subtree must contain values that are less than or equal to the value of a given node, the upper bound on the valid character range for the left subtree is changed to be the value of the current node itself. Similar logic may be applied to get the appropriate arguments for the right subtree.
ConstructBST
Used as: Division One - Level Two:
Value 500 Submission Rate 251 / 450 (55.78%) Success Rate 191 / 251 (76.10%) High Score Eryx for 470.22 points (7 mins 14 secs) Average Score 299.13 (for 191 correct submissions)
This was clearly a combinatorics problem at heart. Here, the shape of a particular BST was described, and coders had to determine the number of distinct input strings that would give rise to a BST of the given shape. One restriction that made the problem simpler, I believe, was the fact that we knew that the first N uppercase characters were used to construct a BST with N nodes.
As a first step toward solving this problem, let's solve the following simpler problem: Find the lexicographically first string that would create a BST with a given shape. (Think about how you would solve this before reading on...) Since duplicate values in the strings are not allowed, we can construct the lexicographically first string by simply counting the number of descendents in the left (or right) subtree of a given node. To better explain the solution, let's use the following example case from the problem: {1, 2, 3, 4, 5}. Recall that using the characters {'A','B','C','D','E'} the following 8 strings generate a tree of the shape shown below: "DBACE", "DBAEC", "DBEAC", "DEBAC", "DBCAE", "DBCEA", "DBECA", "DEBCA".
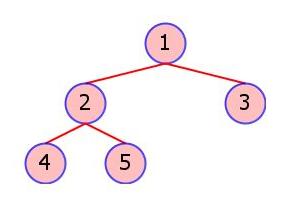
Since the root node has 3 left descendents, we know that the characters {'A', 'B', 'C'} must somehow form the left subtree. Thus, the value of the root node is 'D'. It is clear that the value of the right child of the root is 'E', since this is the only character that has a value greater than 'D'. So, we know that the lexicographically first string must be of the form: "D[ABC]E", where the exact ordering of the characters {'A', 'B', 'C'} is undetermined. But now, we can recursively apply the same logic to the left subtree of the root node, i.e. the tree rooted at the node numbered 2. Thus, we find that the lexicographically first input string is "DBACE".
Now that we have the lexicographically first string, observe that the actual position of the input character 'E' is not important! In fact, as long as 'E' appears after 'D', we can be sure that it will occupy the correct position in the final BST, that is, as the right child of D. In other words, of the 4 characters that appear after 'D', the character 'E' can appear in any position. More generally, the values that comprise the left and right subtrees may be interleaved in any manner, so long as they appear after the common root. The question then becomes, how do we count the number of such interleavings?
This idea of interleaving may be encoded through a binary string. Let 0 represent a value that's part of the left subtree, and let 1 represent a value that's part of the right subtree. Since the root node in our above example has 4 descendents, 1 of which forms the right subtree, the binary strings {'0001', '0010', '0100', '1000'} represent all the ways in which those 4 descendents may be interleaved, while assigning each descendent to a unique subtree (left or right). But note that the number of such binary strings is simply 4 choose 1! Thus, the number of interleavings is simply numTotalDescendents choose numLeftDescendents (or numRightDescendents).
Of course, to finish the solution, we note that this idea applies recursively to all subtrees. Then, for the subtree rooted at node 2, we have 2 total descendents and 1 left descendent, giving us an additional 2 choose 1 = 2 interleavings. So, overall, we are left with 4*2 = 8 interleavings, which is exactly the answer required. The following pseudocode captures the gist of this solution:
// assumes that binom[x][y] stores the binomial coefficient x choose y
function countNumInputs(curNode)
if curNode does not exist (or curNode == null, etc.)
return 1
return binom[curNode.numTotalDescendents][curNode.numLeftDescendents] *
countNumInputs(curNode.leftChild) *
countNumInputs(curNode.rightChild)
function numInputs(tree)
// assumes that the tree has already been annotated with the number
// of left and right descendents for each node
return countNumInputs(root)
Manhattan
Used as: Division One - Level Three:
Value 1000 Submission Rate 100 / 450 (22.22%) Success Rate 43 / 100 (43.00%) High Score reid for 866.17 points (11 mins 32 secs) Average Score 607.40 (for 43 correct submissions)
This problem required rather more insight than just the ability to write a megabyte of code. Congratulations go to reid, who needed less than 12 minutes to solve it.
Let persons A(xA, yA) and B(xB, yB) form the furthest pair and let xA >= xB. The distance between these points is (xA - xB) + |yA - yB|, which can be equal to either
(xA - xB) + (yA - yB) = (xA + yA) - (xB + yB)or
(xA - xB) + (yB - yA) = (xA - yA) - (xB - yB)depending on whether yB is greater than yA or not.
The second parts of these formulae gives us the clue to the solution. The distance between points in the furthest pair can be written in one of the forms, written above. If we will find a pair (A, B) with the maximal value of ((xA + yA) - (xB + yB)) and a pair (C, D) with the maximal value of (xC - yC) - (xD - yD), the furthest pair will be either (A, B) or (C, D) 1.
Obviously, the maximal value of ((xA + yA) - (xB + yB)) is achieved for point A, which has the maximal sum of its coordinates among all input points, and point B, the sum of which is minimal. To find A and B, iterate through all input points, calculating the sum of the coordinates for each point and keeping the indices with maximal and minimal sums. A similar algorithm will find the pair (C, D) with the maximal value of (xC - yC) - (xD - yD), and a simple comparation of pairs (A, B) and (C, D) will give you the answer to the whole problem.
The last trick is to not return (0, 0) in cases when all people live at the same point ((0, 0) is the lexicographically first pair, but it does not represent two different persons). To avoid this, you can add a simple check which will return (0, 1) in all cases when you are trying to return (0, 0).
*1. To prove this we use the following lemma. For any points A and B, the following holds:
|xA - xB| + |yA - yB| >= (xA + yA) - (xB + yB) |xA - xB| + |yA - yB| >= (xA - yA) - (xB - yB)
