
|
Match Editorial |
Thursday, July 6, 2006
Match summary
Division 1 saw an interesting match, with a reasonably easy 250 pointer, a not-so-standard medium problem that startled quite a lot of coders, and a hard problem worth only 900 points.
Petr blazed through the coding phase; he was the first one who had all three problems submitted, and he enjoyed a comfortable lead before the challenge phase. But as the clock was ticking away, Revenger's challenges rocketed him upwards, and soon the difference between the top two was only 1.1 points. In the last few minutes Revenger's challenge streak continued and brought him a well-deserved win in this SRM. Petr finished second. A similar battle was fought for the third place, where Mg9H's five successful challenges decided the bronze medal for this SRM. Twelve other coders solved all three problems correctly.
In Division 2 the problem set contained a 250 that was simple to implement once you understood the problem statement correctly, a tricky 500 pointer, and a hard 1000 point problem. The only one who solved all three problems correctly was omax. Second place went to enefem21, and third place to IgorTPH – the only other coder who successfully solved the hard problem.
The Problems
MeasuringTemperature

Used as: Division Two - Level One:
Value 250 Submission Rate 233 / 337 (69.14%) Success Rate 103 / 233 (44.21%) High Score ikicic for 231.66 points (8 mins 7 secs) Average Score 160.67 (for 103 correct submissions)
This was one of the problems that rewards those who are able to calm down, read the whole problem statement and look at the examples.
The general idea of this problem was clear: given some measurements, identify which of them are valid, and compute the average of the valid ones.
The definition of an invalid measurement was similar to the approach most of us know from secondary school physics: If a measurement gives a value wildly different from all others, throw it away.
The trouble with temperature sensors is that the temperature can vary during the day. Thus the definition said a measurement is invalid if and only if it is wildly different from all other measurements made at roughly the same time. In other words, a measurement is valid if and only if at least one other measurement made at roughly the same time gives a similar value. (The problem statement gave an exact definition, where "roughly the same time" was "within two minutes", and "similar" was "differs by at most 2".)
When implementing a solution probably the best approach is to split it into two parts: first identify the valid measurements, then compute their average. Java code follows.
public static double averageTemperature(int[] measuredValues) {
int N = measuredValues.length;
boolean[] isValid = new boolean[N];
// mark valid measurements
for (int i=0; i<N; i++) {
isValid[i] = true;
if (measuredValues[i] < -273) isValid[i] = false;
// look at nearby measurements
// if none of them is similar, this one is invalid
boolean hasFriend = false;
for (int j=-2; j<=2; j++)
if (j != 0)
if (i+j >= 0 && i+j < N)
if (Math.abs( measuredValues[i]-measuredValues[i+j] ) <= 2)
hasFriend = true;
if (!hasFriend) isValid[i] = false;
}
// compute their average
int count = 0;
double sum = 0;
for (int i=0; i<N; i++)
if (isValid[i]) {
count++;
sum += measuredValues[i];
}
if (count == 0) return -300.0;
return sum / count;
}
InputBoxChecker
Used as: Division Two - Level Two:
Value 500 Submission Rate 171 / 337 (50.74%) Success Rate 23 / 171 (13.45%) High Score PauloftheWest for 463.29 points (8 mins 7 secs) Average Score 330.52 (for 23 correct submissions)
There were two ways how to deal with this problem.
The direct approach
There almost has to be a simple way to compute everything necessary just by looking at the three given integers: smallest, largest, and number. All we have to do is a careful case analysis. First, two clear facts:
- If number > largest, it's surely not a valid prefix.
- If number lies in [smallest, largest] then it is a valid prefix.
Now we may assume that number < smallest.
Let us first solve an easier task: assume that smallest and largest have the same number of digits. In this case the solution is simple:
- Let d be the number of digits in number.
- Let s1 be the number formed by the first d digits of smallest.
- Let l1 be the number formed by the first d digits of largest.
- number is a valid prefix if and only if s1 ≤ number ≤ l1.
For example, 479 is a valid prefix for the range [3138, 5120], because 479 lies between 313 and 512, inclusive.
Now for the general case (when smallest can have less digits than largest): We may split the whole valid range into several shorter ranges, and then conclude that number is a valid prefix if and only if it is a valid prefix for one of the shorter ranges.
For example, we may split the range [879, 12345] into [879, 999], [1000, 9999], and [10000, 12345].
This would already be enough to write a program, however we can make one more observation. If digit counts for smallest and largest differ by more than one, all numbers smaller than smallest are valid prefixes. (In the example above note that one of the ranges is [1000, 9999]. For this range all numbers with up to four digits are valid prefixes.)
Java code follows.
// count the number of digits
public static int digits(int x) {
int cnt=1;
long largest=9;
while (x > largest) { cnt++; largest*=10; largest+=9; }
return cnt;
}
// compute 10^x
public static int pow10(int x) { int res=1; while (x>0) { x--; res*=10; } return res; }
// check whether value lies between s1 and l1 (see text above)
public static boolean isBetween(int smallest, int largest, int value) {
String v = ""+value;
String s = (""+smallest).substring(0,v.length());
String l = (""+largest).substring(0,v.length());
return (s.compareTo(v)<=0 && v.compareTo(l)<=0);
}
public static String[] checkPrefix(int smallest, int largest, int[] numbers) {
int N = numbers.length;
String VALID = "VALID", INVALID = "INVALID";
String[] result = new String[N];
for (int i=0; i<N; i++) {
// handle the simple cases -- when numbers[i]>= smallest
result[i] = INVALID;
if (numbers[i] > largest) continue;
if (numbers[i] >= smallest) { result[i]=VALID; continue; }
// if the range is long enough, all numbers smaller than "smallest" are valid
if (digits(largest) - digits(smallest) >= 2) { result[i]=VALID; continue; }
if (digits(largest)==digits(smallest)) {
if (isBetween(smallest, largest, numbers[i]))
result[i]=VALID;
} else {
// split the range into two sub-ranges, check each of them
if (isBetween(smallest, pow10(digits(smallest))-1, numbers[i]))
result[i]=VALID;
if (isBetween(pow10(digits(smallest)), largest, numbers[i]))
result[i]=VALID;
}
}
return result;
}
The trying-some-possibilities approach
Wow, that was quite a lot of cases one can easily overlook, wasn't it? A general advice for such situations: Grab a pen and paper, write everything down, and make damn sure you didn't miss any case before you start coding.
Or think of a different approach.
The problem statement asked us whether we can add digits to (the right end of) number so that the result lies in the range [smallest, largest]. First, how many digits will we add? Clearly, largest has at most 10 digits, number at least one, thus we will only add up to 9 digits.
Now, for example, let number=347. What numbers can we make by adding three new digits? The smallest one is 347000, the largest one is 347999, and clearly we can make all the numbers between these ranges.
And that's almost all the insight we need.
The entire solution will look as follows: Try all possibilities saying how many digits you'll add. For each possibility, compute the range of numbers you can make. If this range intersects [smallest, largest], you can make a valid value, and thus the input is valid.
C++ code follows:
vector <string> checkPrefix(int smallest, int largest, vector <int> numbers) {
int N = numbers.size();
vector <string> result(N,"INVALID");
for (int i=0; i<N; i++) {
long long currentMin = numbers[i], currentMax = numbers[i];
for (int d=0; d<=10; d++) {
if (currentMin <= largest && currentMax >= smallest)
result[i] = "VALID";
currentMin *= 10;
currentMax *= 10; currentMax += 9;
}
}
return result;
}
FloatingMedian
Used as: Division Two - Level Three:
Used as: Division One - Level Two:
Value 1000 Submission Rate 38 / 337 (11.28%) Success Rate 2 / 38 (5.26%) High Score IgorTPH for 514.89 points (35 mins 38 secs) Average Score 497.25 (for 2 correct submissions)
Value 500 Submission Rate 86 / 295 (29.15%) Success Rate 46 / 86 (53.49%) High Score Petr for 442.87 points (10 mins 28 secs) Average Score 292.17 (for 46 correct submissions)
This problem was maybe a little bit different than most Div1-mediums tended to be in the past months. The problem statement was pretty clear on what you had to do: generate temperatures, compute medians, and (just to minimize output size) keep their sum. The only thing the problem statement didn't mention was how to do it.
And there were quite a plenty of ways. The necessary first observation was that the most straightforward ones will time out. But beyond that, there were still plenty of approaches to choose from. We will present some of the more efficient approaches below.
Heavy artillery approach
Any theoretical computer scientist would just wave his hand and say: Simply store the current set of numbers in a balanced tree. You can add new elements, delete old elements, and query for the median, all in O(log K) time.
Of course, that's easier said than done. The trouble is that none of the tree-like data structures available in the standard libraries support a fast k-th element query ("given k, find the k-th smallest of the stored numbers"). You are on your own here. With a pre-written tree structure you already won, with a textbook and more than half an hour of time you stand a chance.
The thing you have to add to a canonical balanced tree structure is information about subtree sizes: for each node in the tree, keep the count of elements in the subtree rooted at this node. For a particularly easy-to-implement balanced tree structures, check out splay trees and treaps.
Cleverly using what is available
Can we circumvent the need for k-th element queries somehow? The answer is yes. The trick is to split the active elements into a "lower half" and an "upper half".
More precisely, we will keep two multisets of numbers, the first one will contain ceil(K/2) smallest elements, and the other one will contain the remaining ones. The median is the largest element in the first multiset.
C++ code follows:
//
// several helper functions to work with multisets
//
long long popFirstElement(multiset<long long> &S) {
long long result = *(S.begin());
S.erase( S.begin() );
return result;
}
long long popLastElement(multiset<long long> &S) {
multiset<long long>::iterator it = S.end();
it--;
long long result = *it;
S.erase( it );
return result;
}
long long getLastElement(multiset<long long> &S) {
multiset<long long>::iterator it = S.end();
it--;
return *it;
}
//
// the main function
//
long long sumOfMedians(int seed, int mul, int add, int N, int K) {
// generate the temperatures
vector<long long> temperatures;
temperatures.push_back( seed );
for (int i=1; i<N; i++)
temperatures.push_back( ( temperatures.back()*mul+add ) % 65536 );
multiset<long long> lowerHalf, upperHalf;
long long result = 0;
for (int i=0; i<N; i++) {
// add the new temperature
if (lowerHalf.size()==(K+1)/2 && getLastElement(lowerHalf) <= temperatures[i])
upperHalf.insert( temperatures[i] );
else
lowerHalf.insert( temperatures[i] );
// remove the old temperature
if (i >= K) {
if (temperatures[i-K] <= getLastElement( lowerHalf ))
lowerHalf.erase(lowerHalf.find( temperatures[i-K] ));
else
upperHalf.erase(upperHalf.find( temperatures[i-K] ));
}
// update the counts of elements in our multisets
while (lowerHalf.size() > (K+1)/2)
upperHalf.insert( popLastElement( lowerHalf ));
while (upperHalf.size() > K/2)
lowerHalf.insert( popFirstElement( upperHalf ));
// compute the median
if (i >= K-1) result += getLastElement( lowerHalf );
}
return result;
}
The time complexity of this approach is the same as for the previous solution, O(N log K). Note that in each loop we only have to move O(1) elements between the multisets to maintain the balance.
A note to Java users: Java doesn't have a multiset data structure. In the official solution I used a TreeMap to store records of the type "value->multiplicity". For example, if the values were {2, 3, 4, 4, 4, 5, 5}, then lowerHalf would be "2->1 3->1 4->2" and upperHalf would be "4->1 5->2".
Using the limited range of possible values, part one
Another possibility was to notice that the possible values are only integers from a limited range [0,65535]. In this case we can use a data structure that is really simple to implement. I've seen it under many names, the one I like most is "interval/segment trees".
The idea is pretty simple: For each interval of the type [ a*2^b, (a+1)*2^b ] we will keep the count of elements that lie inside the interval.
The same thing once again, this time as a ASCII art picture:
|-------------------------------| |---------------|---------------| |-------|-------|-------|-------| |---|---|---|---|---|---|---|---| 0 1 2 3 4 5 6 7 ...
For each of the segments shown in the picture we will keep the count of elements it contains.
This data structure allows a wide range of operations to be done in logarithmic time: insert an element, erase an element, find the k-th smallest element, find the count of elements within a given range, and so on. We will only need the first three.
Insert and erase are both pretty simple: If there are R=65536 different values, then there are 1+log2 R = 17 levels in our image, and on each level exactly one of the intervals contains the element in question. Thus we have to update 17 stored values (or, in general, the count of operations is logarithmic in the length of the range).
Finding the k-th smallest element will work similarly as binary search does: If there are enough elements in the left half, look for the k-th element there, otherwise subtract the count of elements on the left from k, and look at the right half. This can also be done in logarithmic time.
C++ code follows:
int tree[17][65536];
void insert(int x) { for (int i=0; i<17; i++) { tree[i][x]++; x/=2; } }
void erase(int x) { for (int i=0; i<17; i++) { tree[i][x]--; x/=2; } }
int kThElement(int k) {
int a=0, b=16;
while (b--) { a*=2; if (tree[b][a]<k) k-=tree[b][a++]; }
return a;
}
long long sumOfMedians(int seed, int mul, int add, int N, int K) {
// here you generate the temperatures -- same as in previous code
long long result = 0;
memset(tree, 0, sizeof(tree));
for (int i=0; i<N; i++) {
insert(temperatures[i]);
if (i>=K) erase(temperatures[i-K]);
if (i>=K-1) result += kThElement( (K+1)/2 );
}
return result;
}
A final note: Our implementation is lazy and it uses O(R log R) space, where R is the size of the range of allowed values. Clearly the total number of segments is 2R-1. Moreover, the information contained in them is redundant. A simple optimization is to store the information for the left half only. Using this optimization, a single R-element array is enough to store the tree. Bitwise operations can be used to simplify the implementation even more.
Using the limited range of possible values, part two
Yet another possible optimization: The pseudorandom number generator generates the next number based on the previous number only. This means that once a generated value repeats, we entered a cycle, and from now on the same sequence will be generated over and over.
Thus we can do a brute-force solution until all the active temperatures lie in the cycle. Then we compute the medians for one complete iteration of the cycle, and count each of them the right number of times.
Other approaches
A few contestants managed to squeeze in solutions that maintained the active temperatures in a sorted array. The constraints suggested that this solution may pass, if it can be optimized enough, but still it was a gamble, and I suspect that there were many who failed, and only a few who managed to optimize their solutions enough. (E.g., one solution I've seen used memcpy to move large chunks of the sorted array.) Only go this way if you are out of any other ideas, and make sure to test your solution on large timeout cases before submitting.
There were also some other ways to solve the problem, e.g. instead of the complete interval tree one could use 256-element buckets to store partial information about the temperatures. This may not be more simple to implement, but it surely is easier to think of if you never implemented an interval tree before.
Final notes
This problem (a floating median) is a common problem in meteorological software. How would you compute a floating minimum? And how about a floating average? (If you found the last one too easy: what about a floating average that doesn't accumulate rounding errors over time?)
PyramidOfCubes
Used as: Division One - Level One:
Value 250 Submission Rate 263 / 295 (89.15%) Success Rate 141 / 263 (53.61%) High Score neo_bd for 245.09 points (4 mins 2 secs) Average Score 162.20 (for 141 correct submissions)
One image is better than a thousand words, so we will start by looking at the images from the problem statement once again.
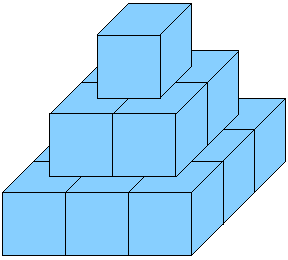
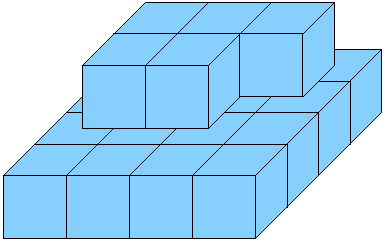
The most problematic part of the surface is the top side. From some of the faces only a half is visible, from some of them three fourths... looks complicated, doesn't it?
Well, it doesn't. The partial areas may have any shapes they please, still the total area is an integer. To see why it is so, just look at the pyramid from the top. The total area we see is the total area of all the top sides – but also it is the total area of the bottom side of the pyramid.
We are left with two tasks: determine how the bottom of the pyramid looks like, and count the total area of the vertical faces.
The bottom side will almost always be a square. If we have enough cubes to build a pyramid of size N≥3, we have enough cubes to build a (N+1) by (N+1) square. So the only cases where this has to be handled are when we have less than 14 cubes. More precisely, the bottom side is not a square only for N=2, 3, 6, 7, and 8. The values 6, 7, and 8 made good challenge cases.
A simple way to handle this: if we don't have enough cubes to build the bottom square, they all sit on the bottom, thus the total area of the bottom side is the count of cubes we have.
The most natural solution when counting the vertical faces is to process the pyramid by levels, just as it is built. For each level, find out the number of "rows" and "columns" of cubes you can (at least partially) fill. The total number of vertical faces on this level is then 2*(rows+columns), and this holds even if the last row is not complete. (Look at the image of the incomplete pyramid, and use the same argument as for the top side.)
Usually the number of columns will be equal to the "size" of the current level, but this doesn't have to be true all the time. For example, for K=10 the result is a 3 by 3 square with a single cube standing on it. This was also one of the more popular challenge cases.
Java code follows:
public double surface(int K) {
// find the right pyramid size
int N = 1, cubes = 1;
while (cubes < K) { N++; cubes += N*N; }
double result = 0;
// handle top and bottom sides
if (K >= N*N)
result += 2*N*N;
else
result += 2*K;
// handle vertical sides row after row
while (K > 0) {
int rows = (K+N-1)/N; // =ceil(K/N)
if (rows > N) rows = N;
if (rows > 1)
result += 2*(rows+N);
else
result += 2*(K+1);
K -= N*N;
}
return result;
}
BoxTower
Used as: Division One - Level Three:
Value 900 Submission Rate 84 / 295 (28.47%) Success Rate 45 / 84 (53.57%) High Score Petr for 819.52 points (9 mins 5 secs) Average Score 637.86 (for 45 correct submissions)
This task didn't cause much trouble FOR people comfortable with memoization and/or exponential-time dynamic programming. Still, not every coder at TopCoder has years of experience under his belt. Without seeing and solving ten similar problems, finding the right idea on how to solve this problem is hard. And this is why this problem was used as the hard problem, even if the count of successful solutions was similar to the medium problem.
Suppose that we have a partially built tower. The only things that matter now are: which boxes are still unused, and what does the top side of the current tower look like.
The top side is a side of one of the used boxes. Each box has (up to) three different sides. Thus the total count of different situations we can get into is 2N*N*3. For each of the situations we will compute the best tower.
As usual, there are two isomorphic views of this problem. We can either turn it into a dynamic programming solution that processes the situations with less free boxes first, or we can write a recursive function and memoize the values it computes.
Java code of a memoized solution follows.
// indices into cache:
// - a bitmask with unused cubes,
// - the index of the topmost used cube
// - the index of its vertical side
int[][][] cache;
int solve(int unused, int top, int side, int[][] C) {
// return if already computed
if (cache[unused][top][side] > -1)
return cache[unused][top][side];
// handle the base case
if (unused == 0) return 0;
int N = C.length;
int result = 0;
// try to add each of the unused cubes, in each rotation
// if it fits, recursively compute the best way to place the rest
for (int next=0; next<N; next++)
if ((unused & (1<<next)) > 0)
for (int s=0; s<3; s++) {
// the top side of the lower cube
int lox = Math.min( C[top][(side+1)%3], C[top][(side+2)%3] );
int loy = Math.max( C[top][(side+1)%3], C[top][(side+2)%3] );
// the bottom side of the upper cube
int hix = Math.min( C[next][(s+1)%3], C[next][(s+2)%3] );
int hiy = Math.max( C[next][(s+1)%3], C[next][(s+2)%3] );
if (hix <= lox && hiy <= loy)
result = Math.max( result, C[next][s] + solve(unused ^ (1<<next), next, s, C) );
}
// store and return the result
return cache[unused][top][side] = result;
}
public int tallestTower(int[] x, int[] y, int[] z) {
// initialize the cache
int N = x.length;
cache = new int[1<<N][N][3];
for (int[][] a : cache) for (int[] b : a) for (int c = 0; c < b.length; c++) b[c] = -1;
// move the dimensions into a 2D array
int[][] cubes = new int[N][3];
for (int i=0; i<N; i++) { cubes[i][0]=x[i]; cubes[i][1]=y[i]; cubes[i][2]=z[i]; }
// try each cube as the bottom one, each time find the best solution
int result = 0;
for (int b=0; b<N; b++)
for (int s=0; s<3; s++)
result = Math.max(result, cubes[b][s] + solve( ((1<<N)-1) ^ (1<<b), b, s, cubes) );
return result;
}
A slow but cute solution
One should note that there is a neat O(3N*poly(N)) solution: For each box, try 3 possible orientations (it only matters which side is vertical). Now, order the boxes according to the area of their bottom side, and use a simple DP to compute the height of the best tower. (This solution can handle up to 11 boxes within the time limit, maybe you can squeeze 12 out of it, if you try hard.)
