April 30, 2021
Job Processing with Databricks

DURATION
9mincategories
Tags
share

This article will discuss job processing using Spark & Databricks. Databricks is a software platform that executes over Apache Spark. It helps create clusters and a workspace to execute jobs in a cluster.
Introduction: Job Processing
Databricks was developed by the creators of Apache Spark. This software is used for data engineering, data analysis, and data processing using job API. Data engineers, scientists, and analysts work on the data by executing jobs. A job is a method for app execution on a cluster and can be executed on the Databricks notebook user interface. A job can be an analytics or data extraction task. Job execution results can be managed and read by using CLI, API, and alerts.
Databricks Workspace
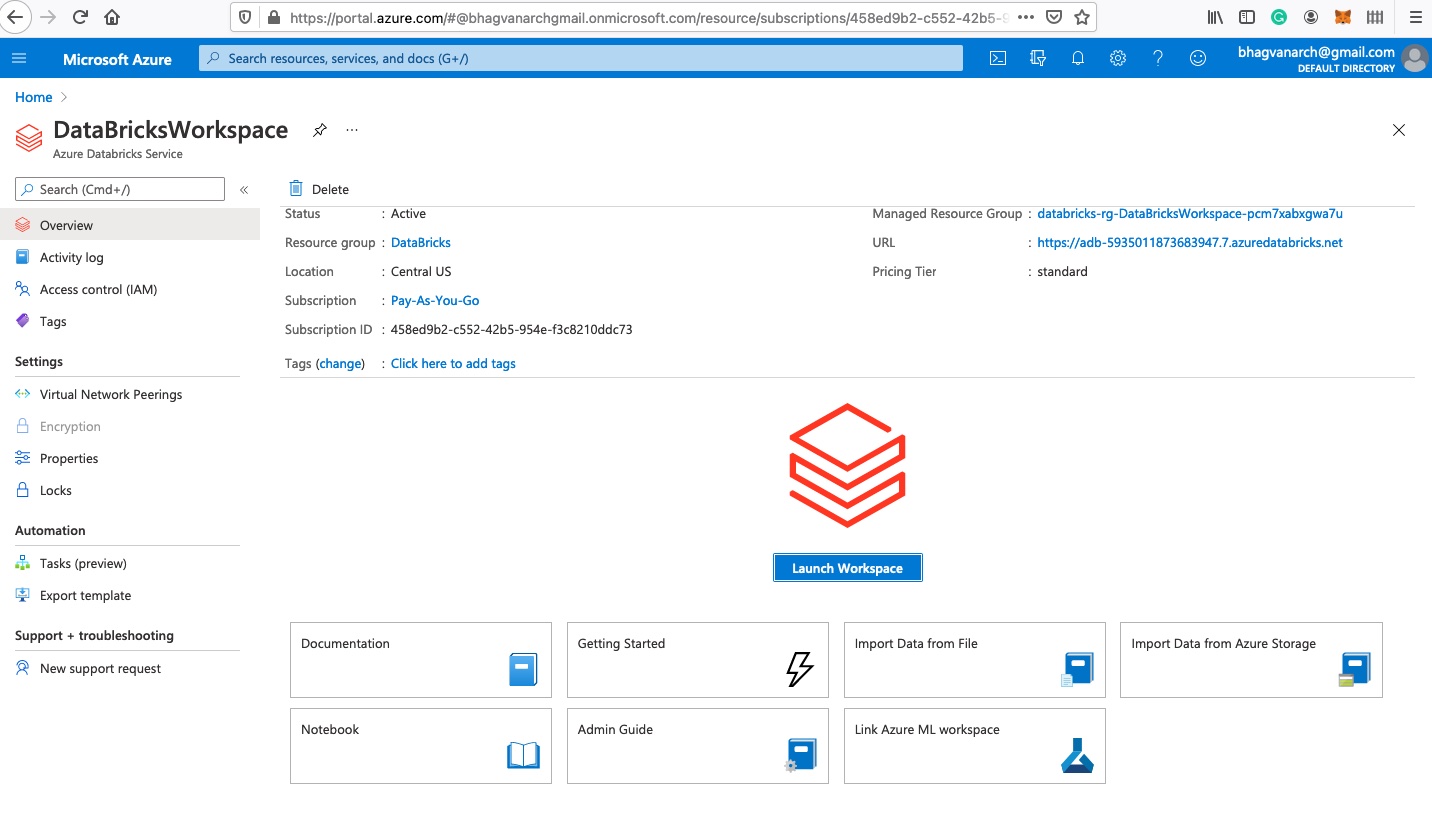
Job Creation
You can create a job by launching the workspace. After you launch the workspace, you will see the figure below:
Azure Databricks
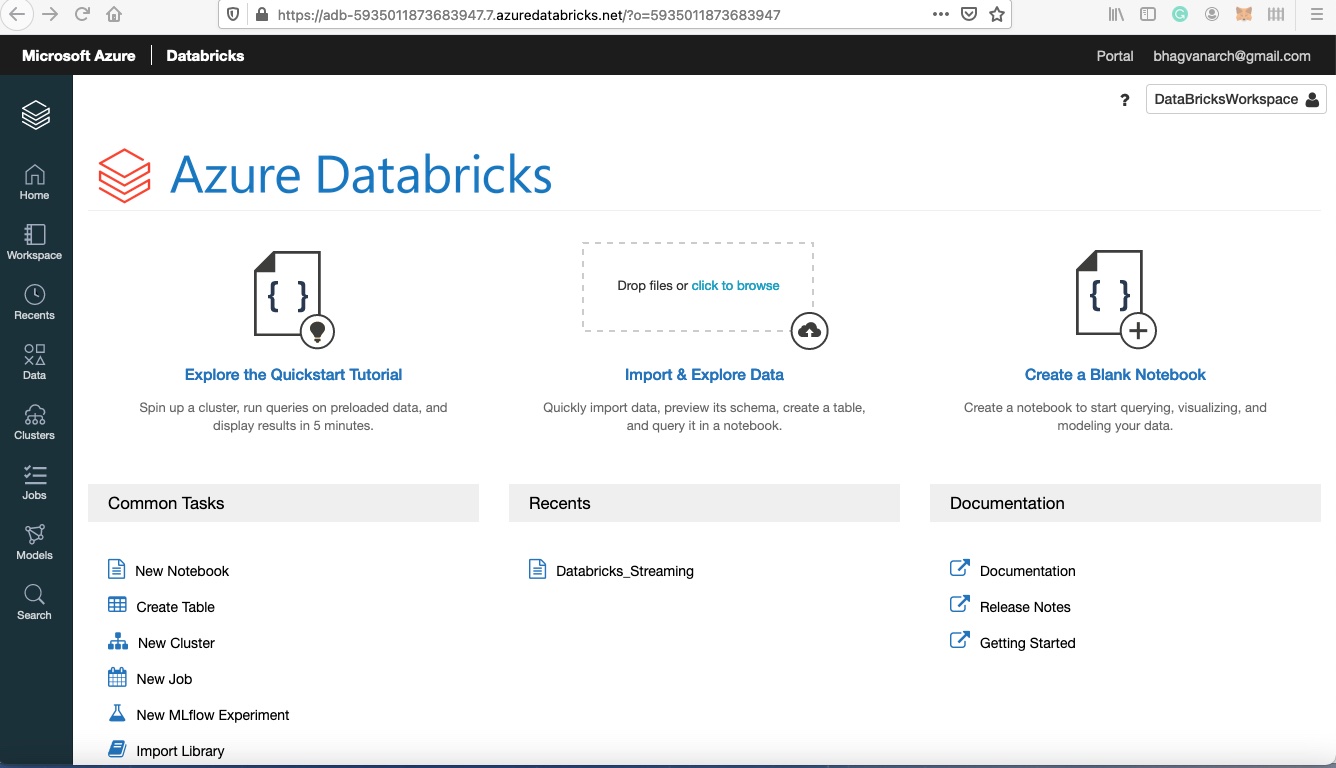
You can click on New Job in the common tasks column. The job detail page will be shown; a snapshot is attached below.
Job Detail
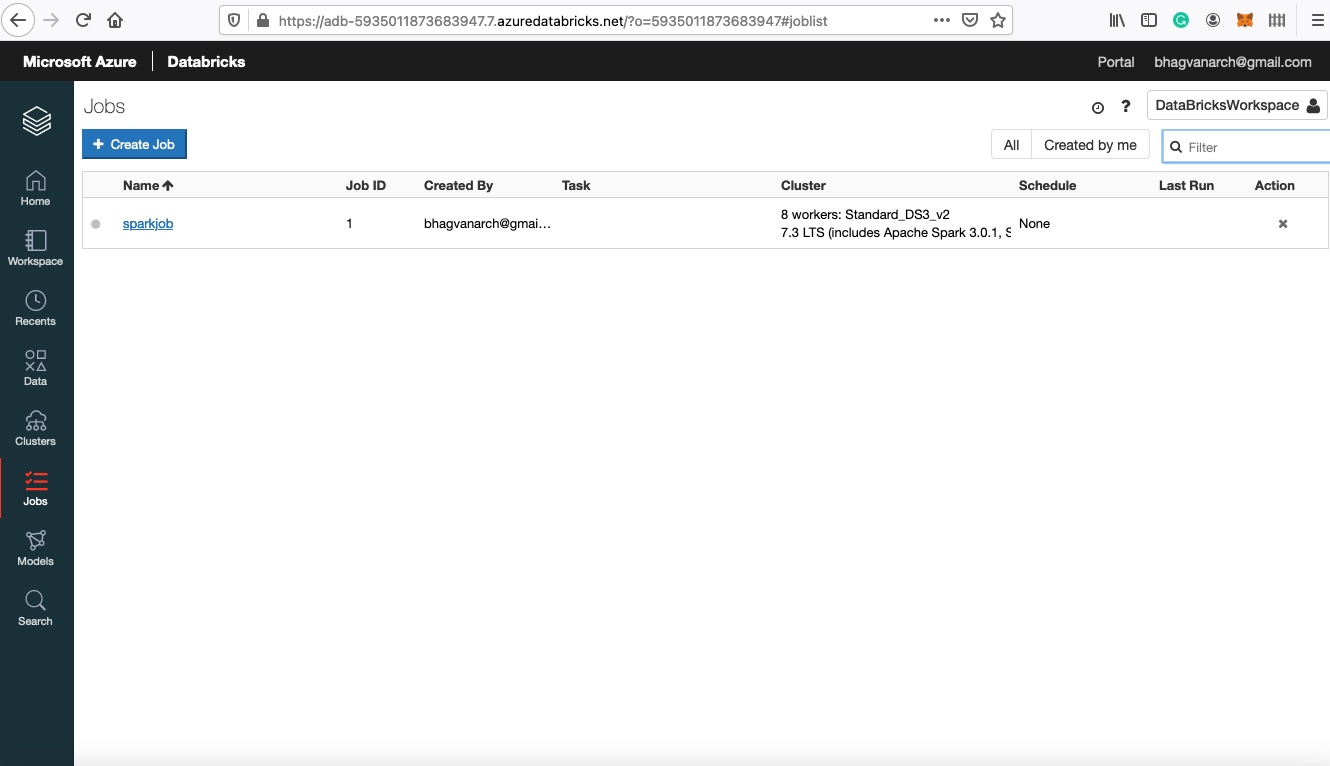
You can enter the name as sparkjob. Sparkjob is created as shown below.
Job Detail
Job Information
Databricks has support for Jupyter notebooks which can be versioned on GitHub and Azure DevOps. You can select the run type as manual. The task can be selected as a Notebook. You can specify the notebook as shown below:
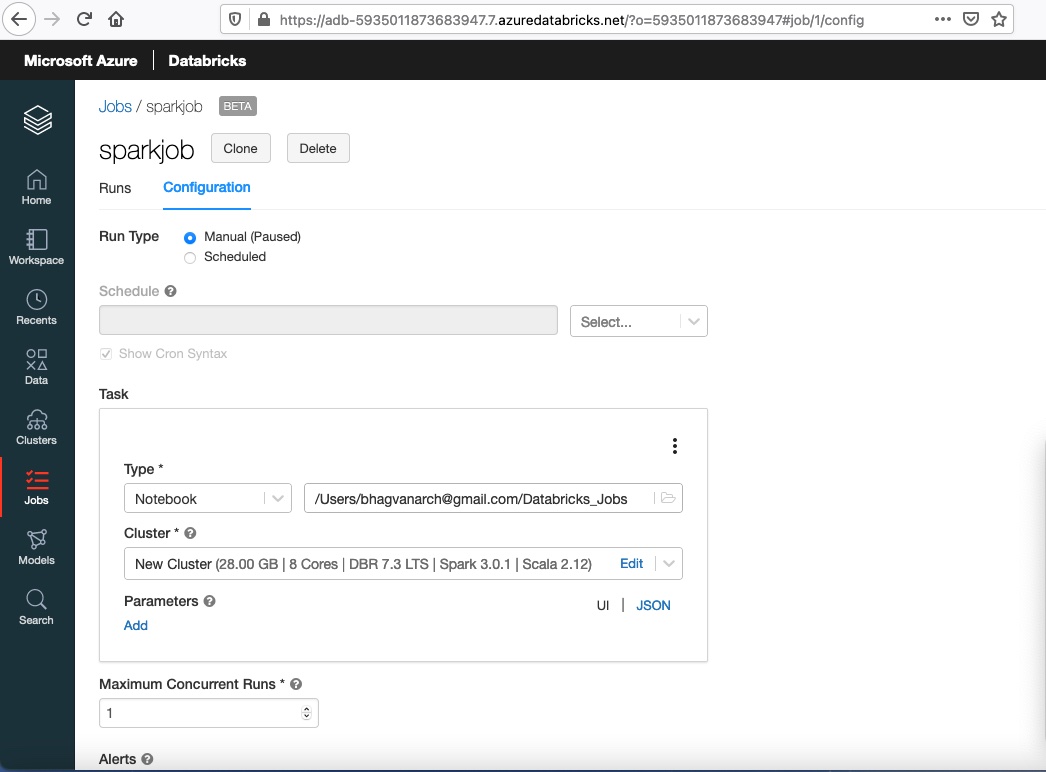
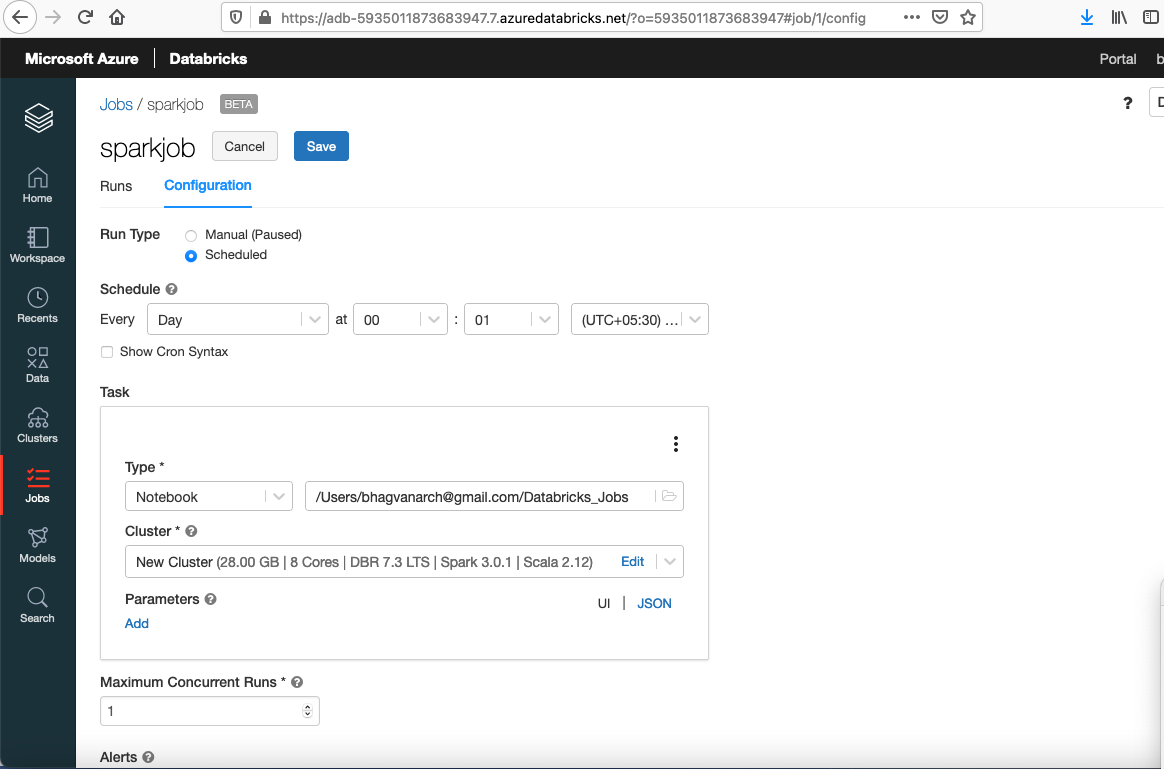
Jobs can be scheduled using the configuration tab as shown below.
Job Configuration
Job Execution
You can manually run the job using the configuration as shown.
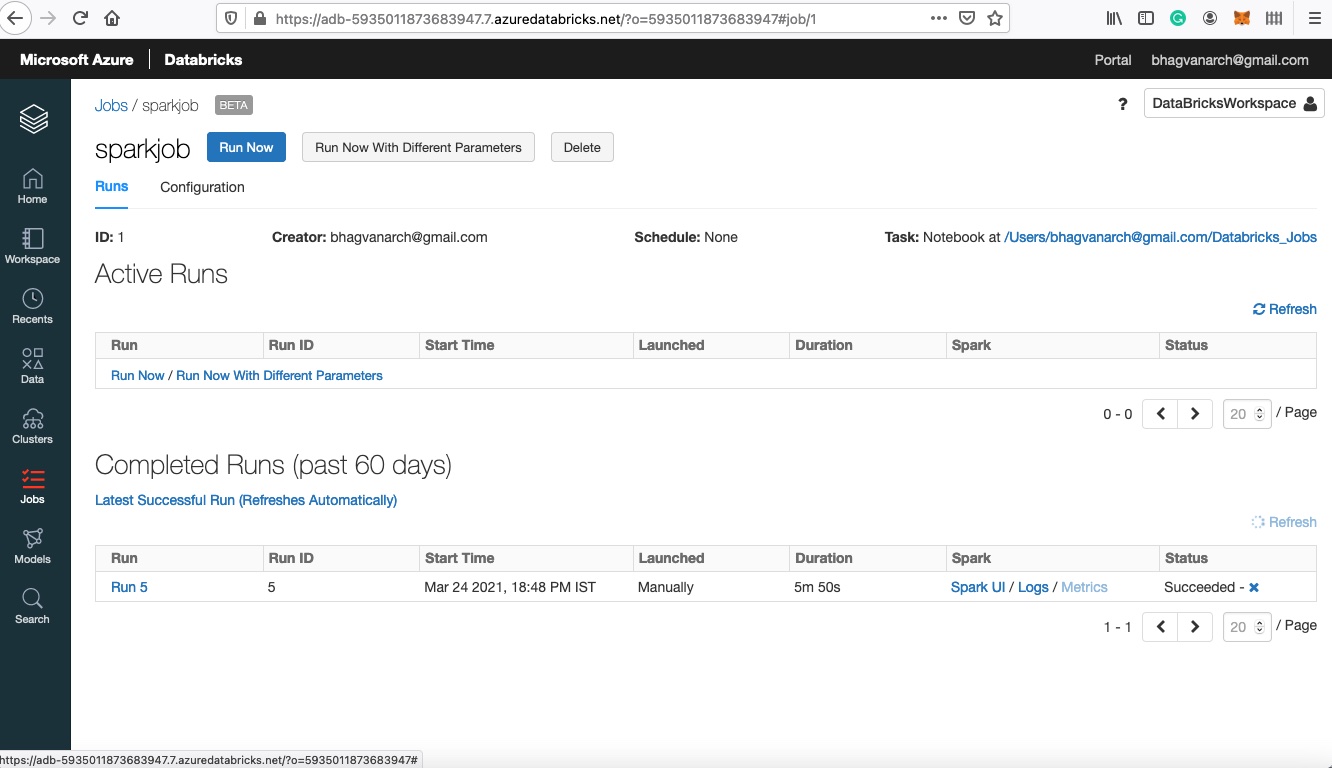
Job Execution
The output can be accessed by clicking on the completed runs. The output is shown below:
Job Notebook Output
Job Editing
You can edit the job using the job detail page as shown below:
Job Detail
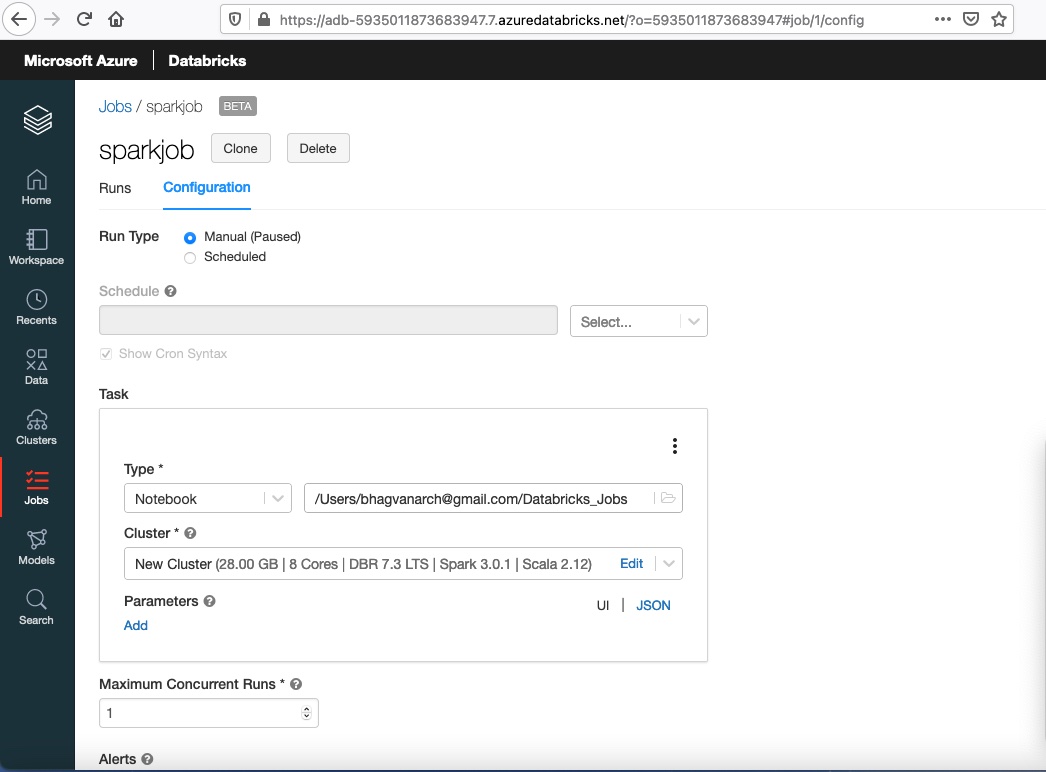
You can clone the job using the clone button shown in the figure above.
Job Deleting
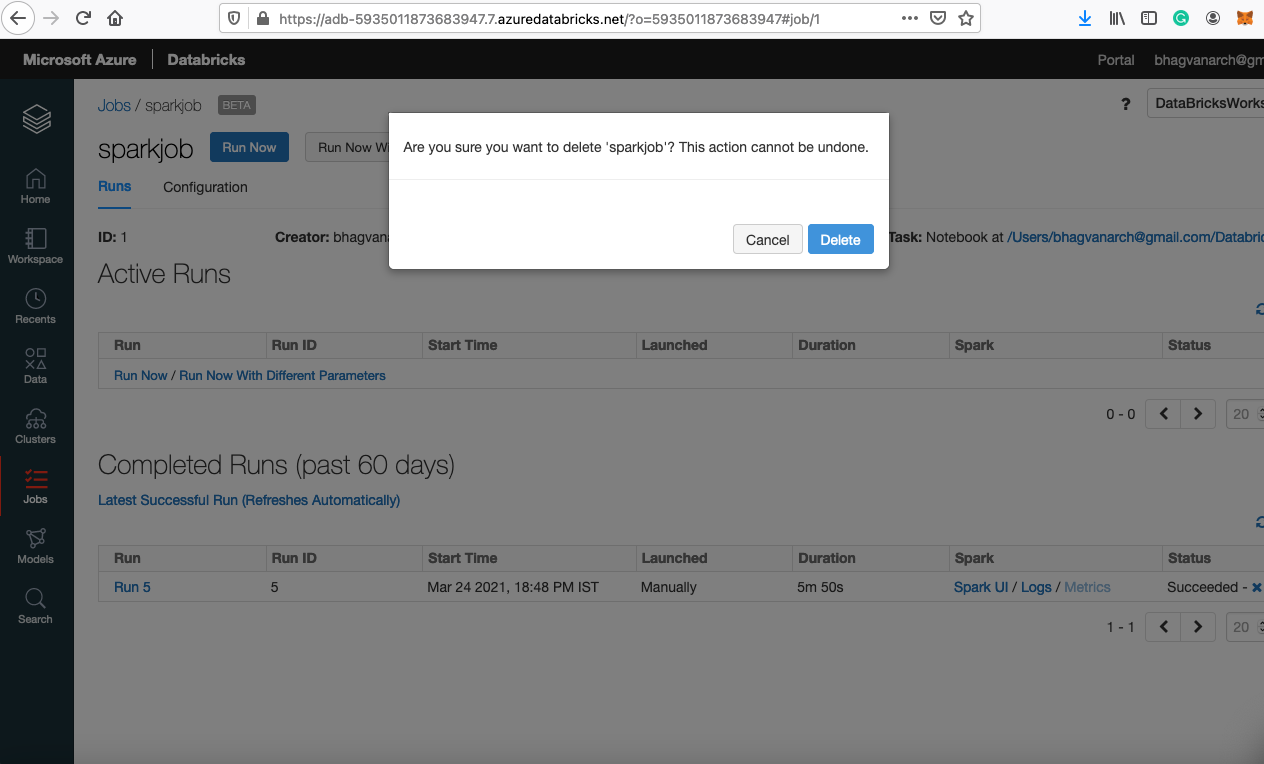
You can delete using the delete button next to the clone button. You can confirm the delete by clicking on the delete button.
Delete Job
Job Related Alerts
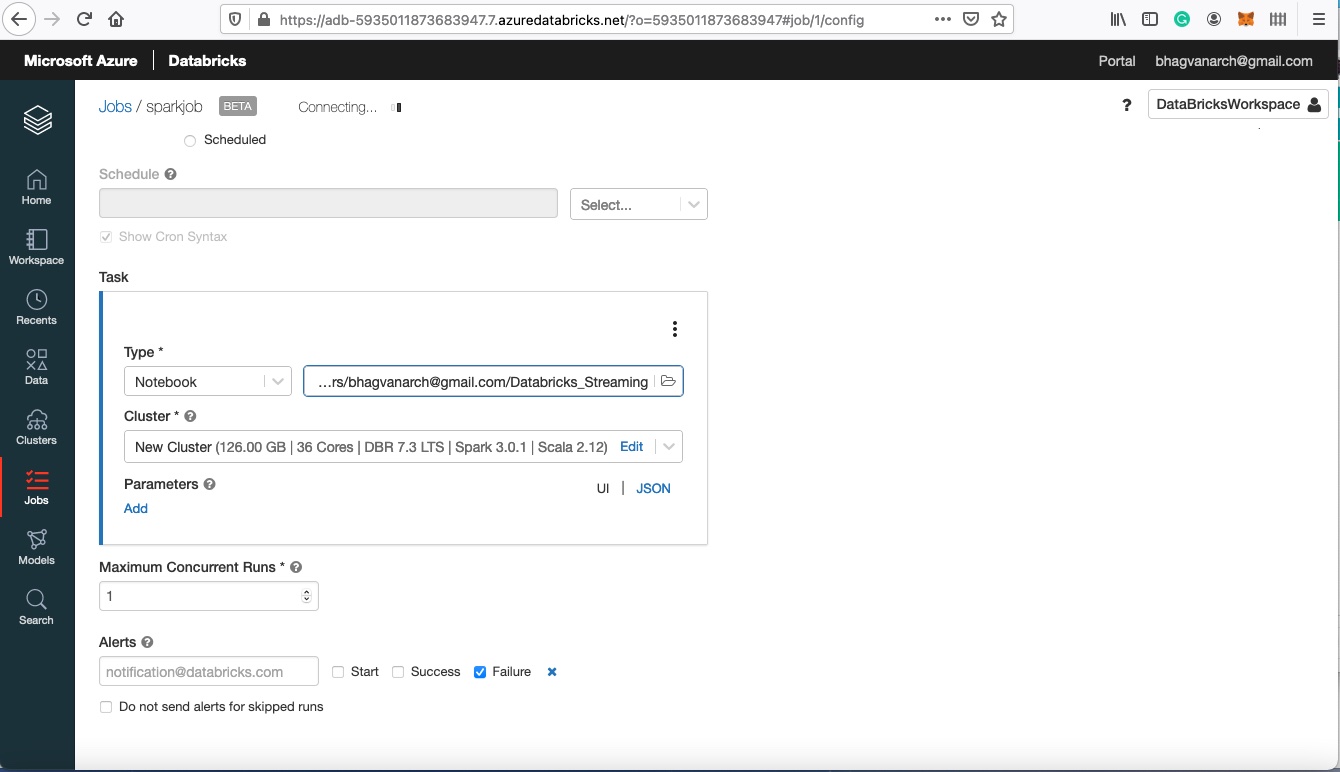
You can create job related alerts by choosing the alerts as shown in the figure below.
Job Alerts
Job Access Control
You can control job access using permissions on the jobs for admin and owners. You can select the users or user groups who can see the job results as well as the users who can execute the job.
Job Exporting
You can export the job using the export option on the job notebook. The snapshot is shown below.
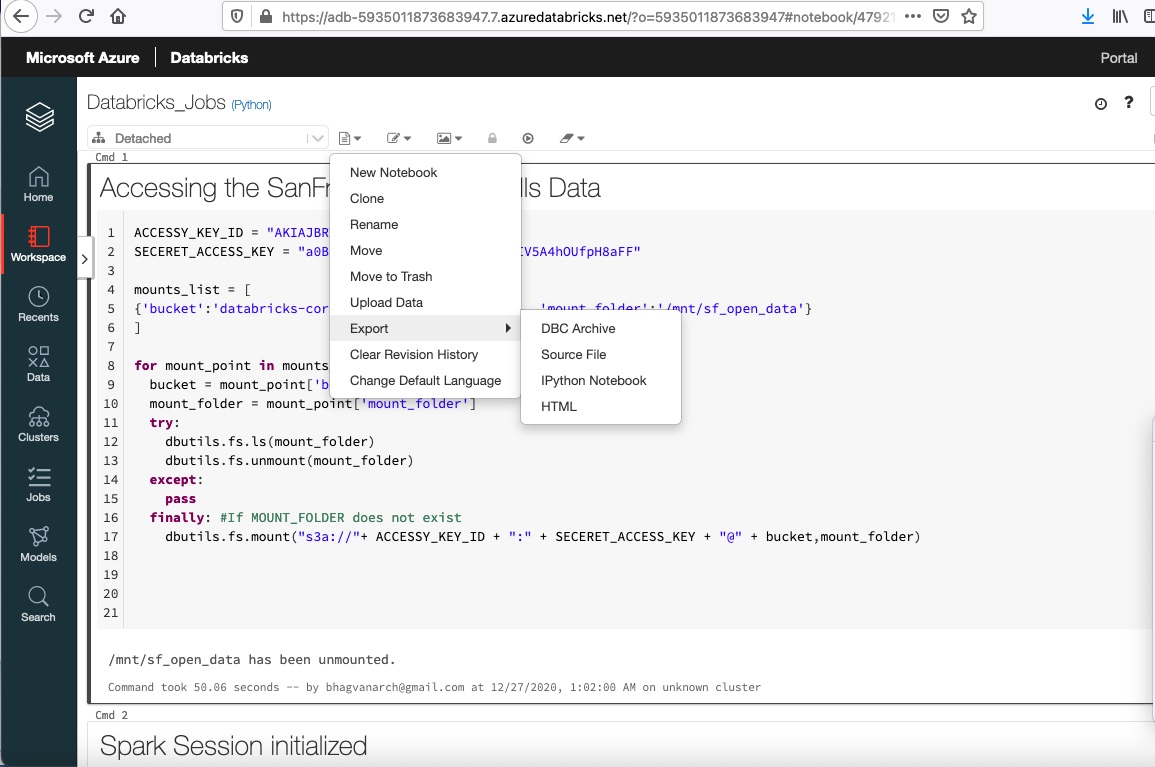
You can also export the output from the notebook and the logs. The format of the export can be in HTML. You can use the Job API to share the logs to DBFS or S3.
In the next part of the series, we will look at creating a Spark cluster in Databricks Workspace
References: