January 26, 2021
Introduction to Streaming: Spark & Databricks

DURATION
20mincategories
Tags
share

“Information is the oil of the twenty-first century, and analytics is the combustion engine.” – Peter Sondergaard
This article will talk about streaming techniques using Spark and Databricks. Databricks is a software platform that executes over Apache Spark. It helps in creating a workspace to execute Spark data frames using the data from AWS S3. The data source can be AWS Kinesis, Kafka stream, flat files, and message queue.
Introduction to Streaming: Using Databricks
Databricks was created by Apache Spark founders. This platform helps data engineers, scientists, and analysts to perform data engineering, data analysis, and data processing. It has features related to interactive notebook creation, Spark runtime, and Big Data SQL query engine. It has ETL, analytics, and machine learning modules. Databricks can interact with other Azure services like Event Hub and Cosmos DB. Clusters that can be auto-terminated and auto-scaled can be created on the Databricks workspace and virtual machine nodes can be assigned to the cluster for execution. Spark Structured Streaming and Delta Lake are the important components in the Databricks platform.
Now let us look at streaming data use cases where data can come from different sources. A producer application will be pushing the data for the consumer application to process the data.
Databricks Streaming Architecture
Databricks supports Jupyter Notebooks and they can be versioned on github and Azure DevOps. Databricks is based on Apache Spark with other open-source packages. Developers can spring up clusters using Spark for big data processing. Auto-scaling and auto-termination features are provided by Azure Databricks.
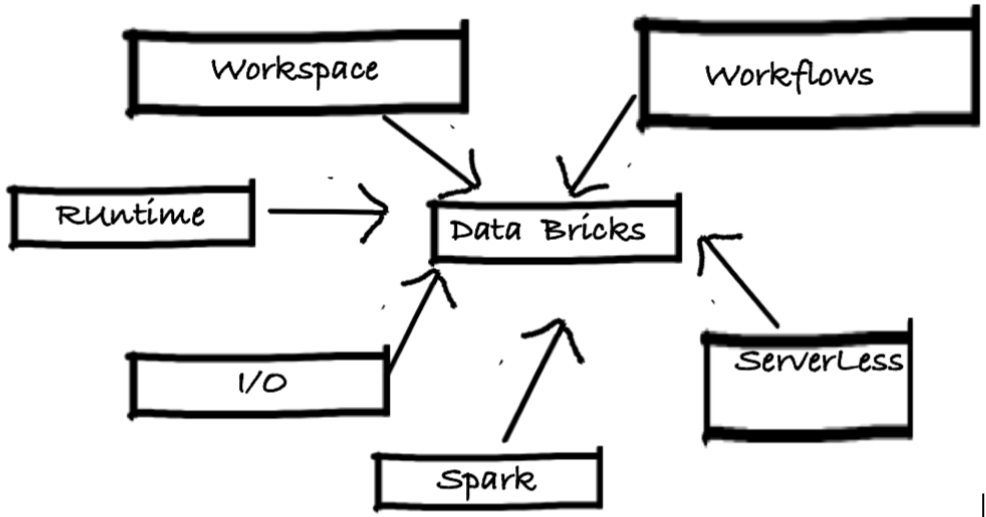
The streaming component has features to handle data from csv and transform to json. Event Hub can access the data and execute transformations related to IOT Hub. Routing can have rules for pushing the data to different sources. Data can be sent to a database (Cosmos DB) and SQL queries can be executed on the database.
Data Frames & Data Sets
Databricks platform can handle data sets and create data frames from them. Data frames are immutable table data structures that can have the result persisted in themselves. Transformations can be performed on the data frame like sorting, filtering, grouping, and selecting.
The sample data frame used in this article is shown below in the notebook: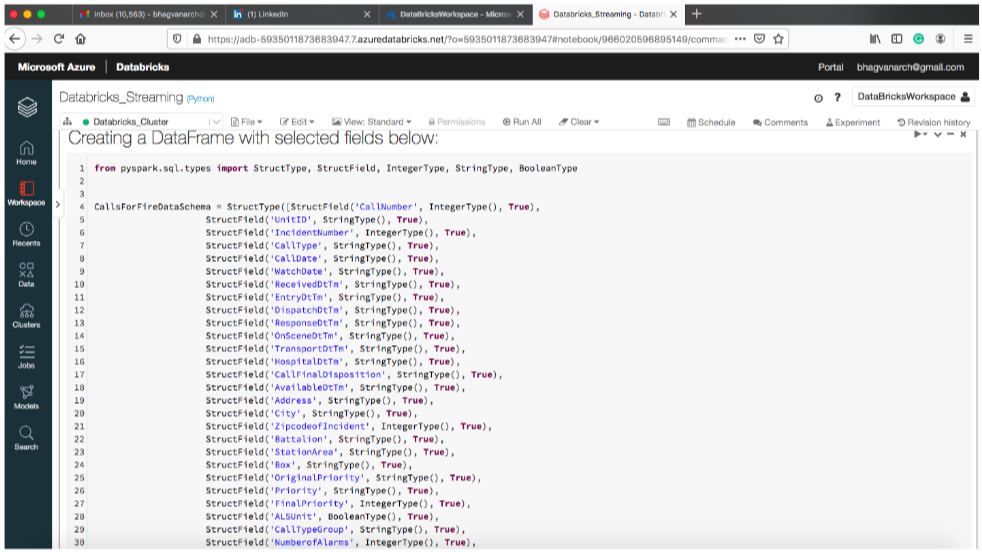
Databricks Data Lake
Databricks platform has support for creation of Data Lake. Data Lake has structured, unstructured and non tabular data persisted in a repository. It has features for object storage and transforming different data formats such as images, videos, binary files, and flat files. It can be used for aggregating data from enterprise different locations and creating reports and dashboards using that data. The advantage is persisting the data as it is without new schema creations and transformations.
Databricks Account Creation
A Databricks account can be created on a trial or pay as you go basis. The pay as you go model charges you for the usage of underlying virtual machines.
You can start creating the Databricks account as shown below: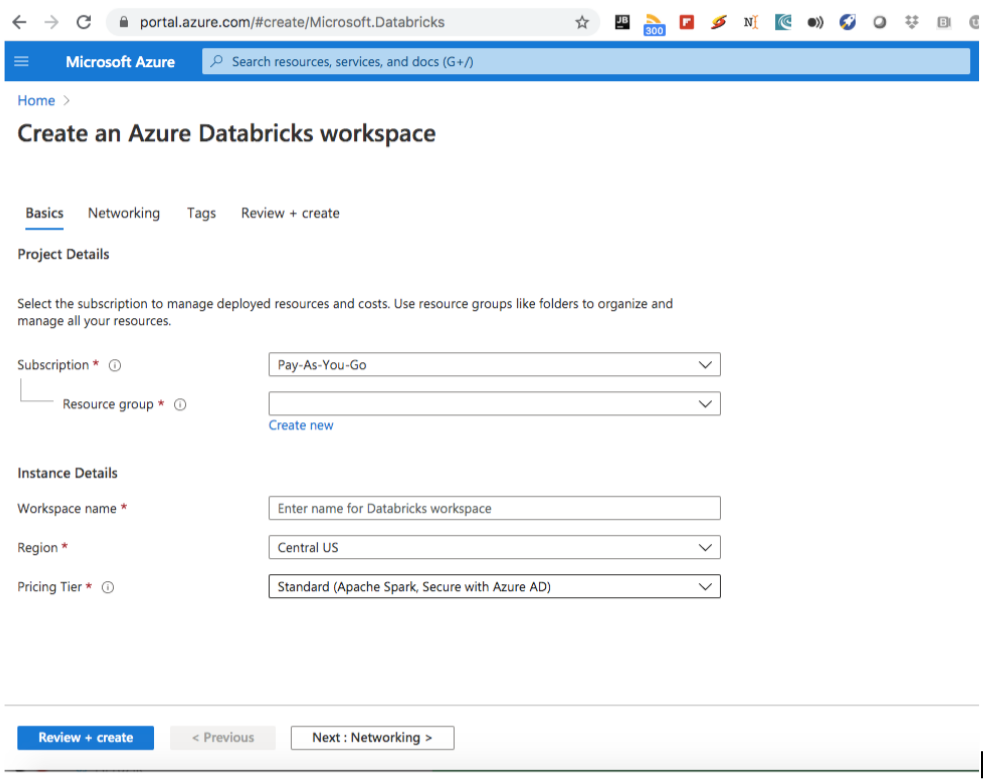
You can see the workspace created for your streaming data.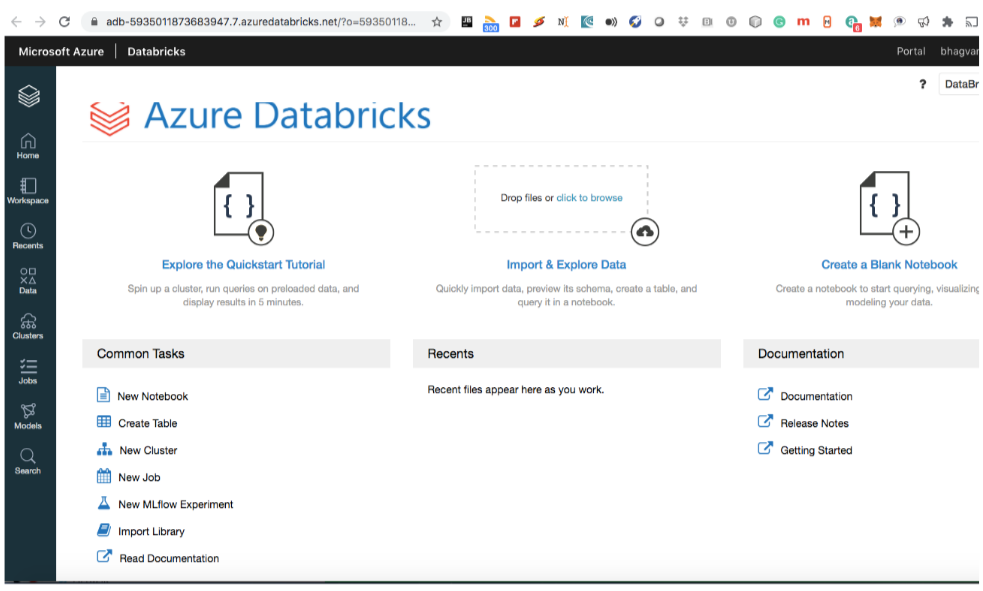
The left menu has items for cluster creation and notebook creation.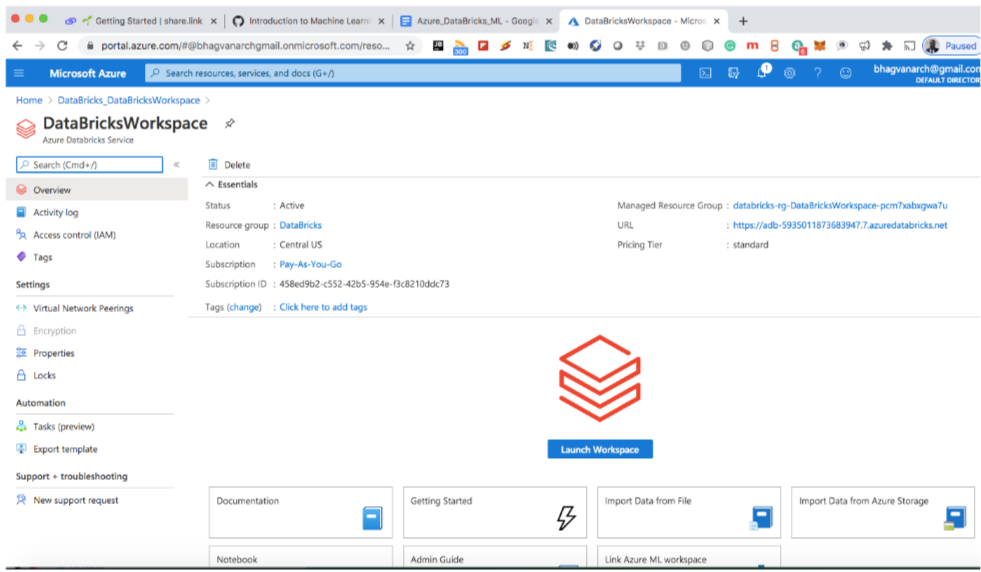
Cluster Creation
You can create a cluster as shown below: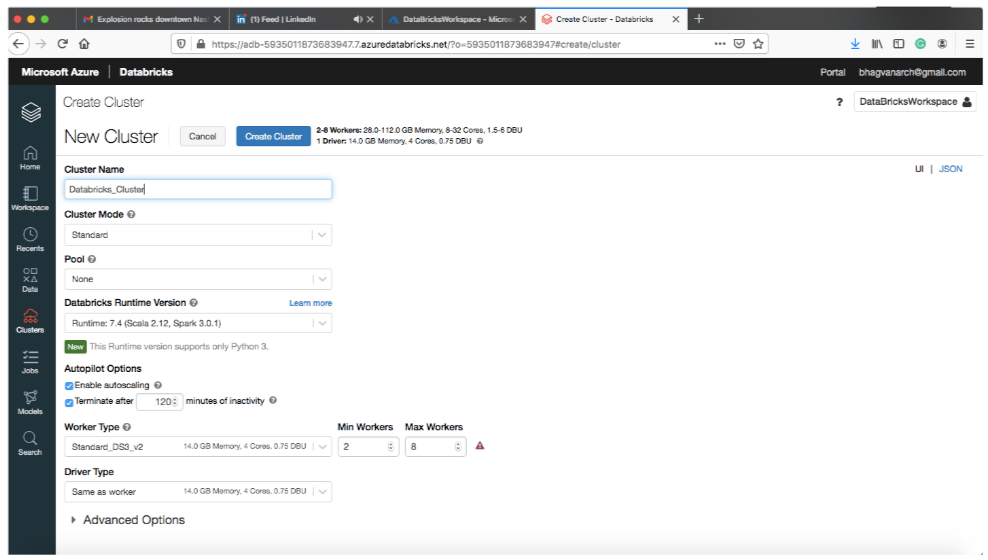
Input Data Creation
You can create a notebook in the cluster created above: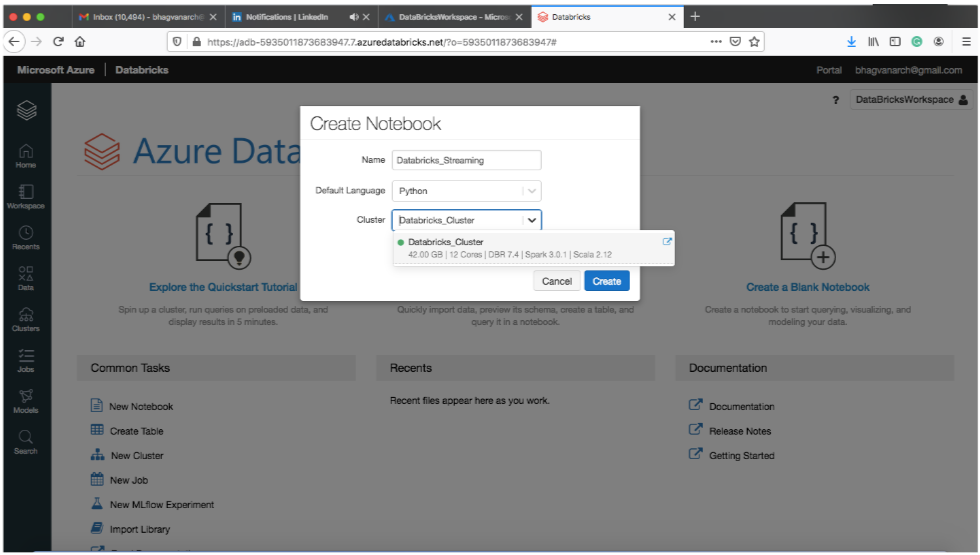
After creating the notebook, you can start writing the code related to data processing.
Data Stream Processing
A data sample from SanFranscisco Fire Calls is used in this notebook. The data from AWS S3 is mounted to the Azure file system.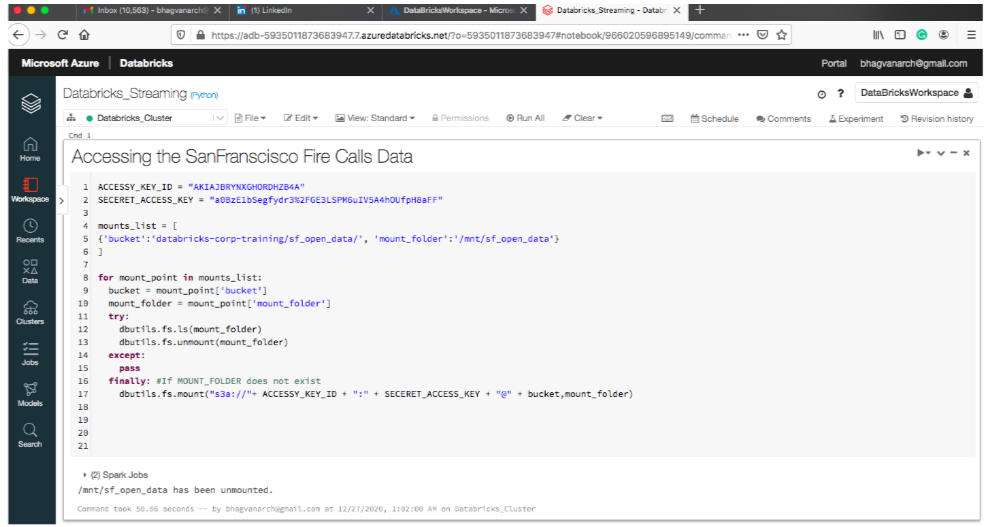
Spark session is initialized below: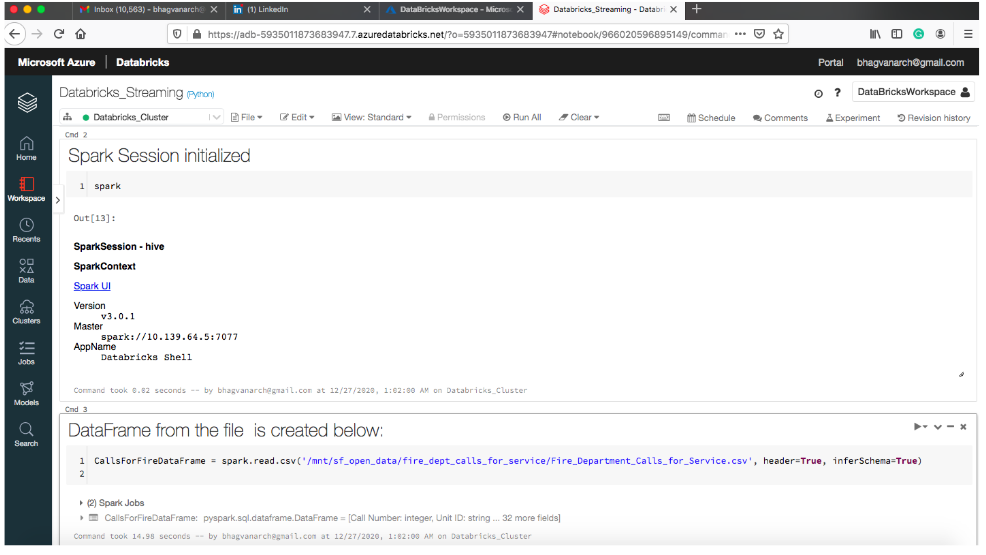
After creating the data frame, the query is executed for getting the first five rows.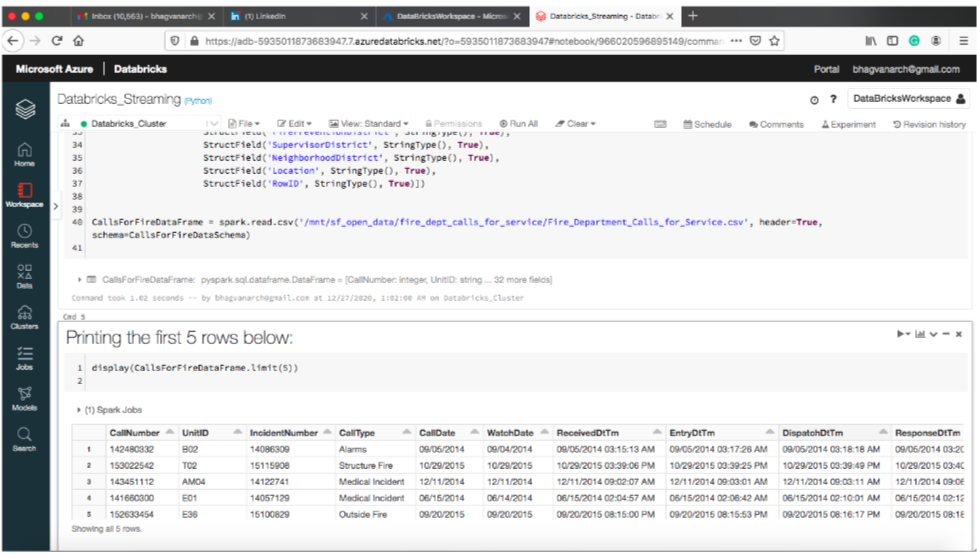
You can print the columns in the data frame as shown below: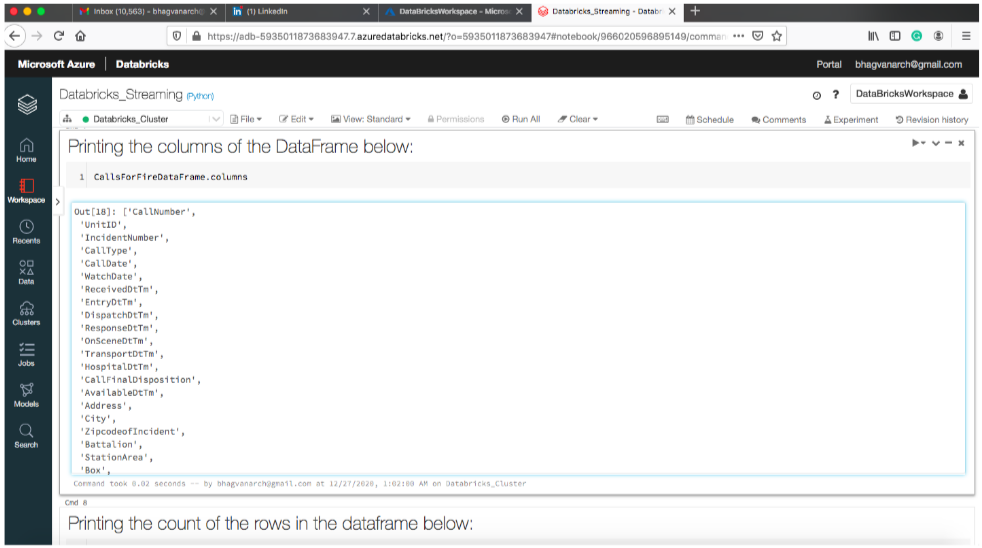
You can print the total count of the rows in the dataframe. The below snapshot shows the top seven call types printed in the dataframe.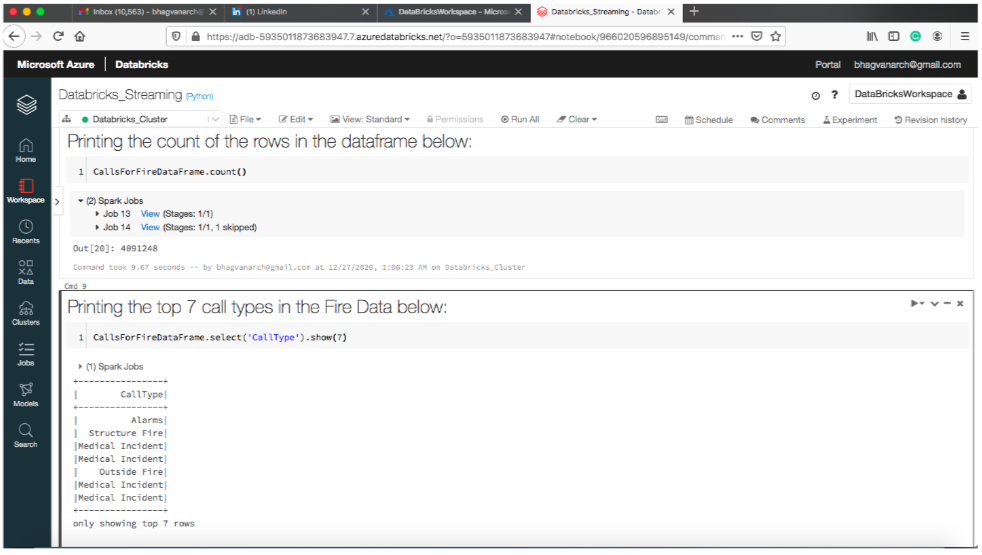
The below snapshot shows how to print distinct call types - top twenty-five rows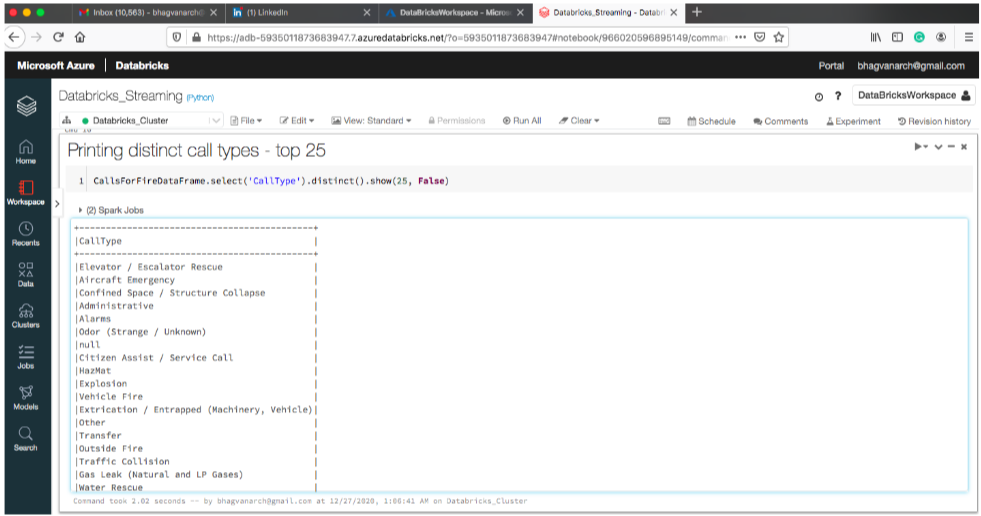
You can group the data by call types and sort the data in ascending order by count column. This is shown below: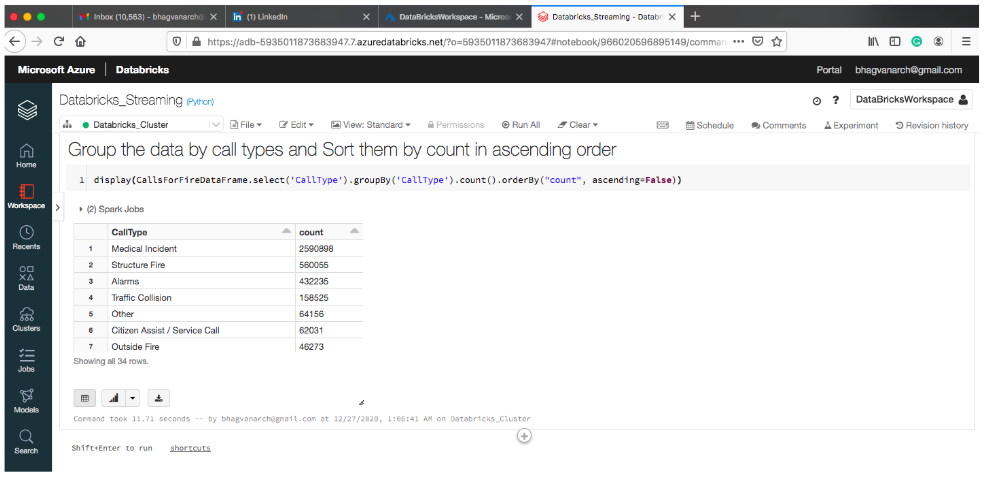
Data Aggregation
Data can be aggregated from multiple data sources and from various formats using transformations and joins. The output can be stored in different destinations in the Databricks platform. You can use aggregators for summing up data in a data set to calculate the output. An aggregator has input type, intermediate type, and output type elements in the interface.
Azure Databricks - Data Warehousing
The Databricks platform can engineer data with Azure Data Factory, Azure Data Lake Storage, and Azure Synapse Analytics. Azure Databricks has features related to data warehousing and providing dashboards and reports. Databricks platform provides a transactional storage layer for data management with reliability and scalability. Power BI can be integrated with Databricks for analytic capabilities. Workspaces are secured with features such as compliant and private analytics workspaces. Big data sets are executed with continuous integration, continuous deployment tools (CI/CD) and DevOps tools.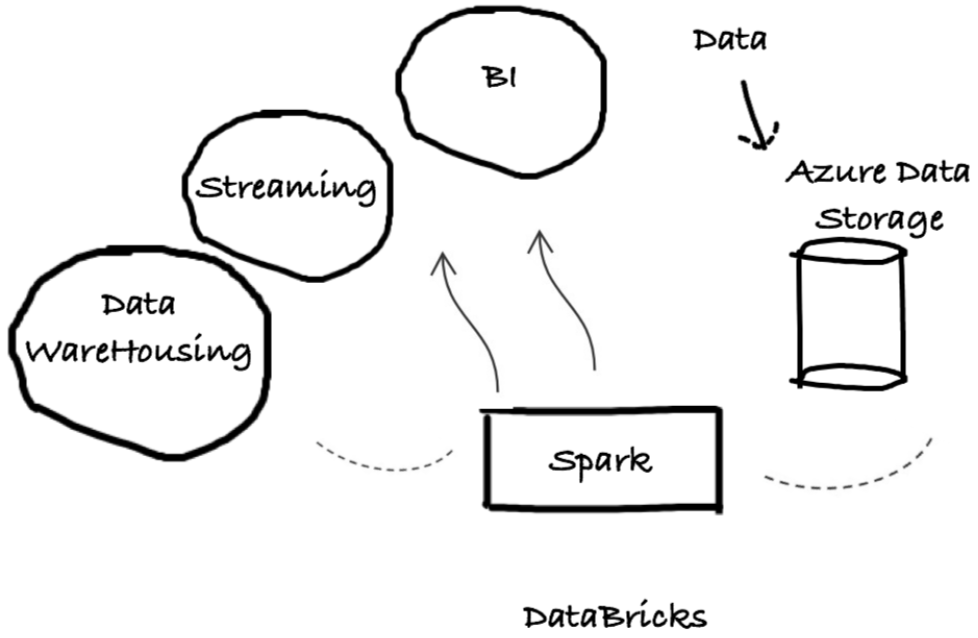
You can access the notebook at this link : https://github.com/bhagvanarch/databricks/blob/main/Databricks_Streaming.ipynb
In the next part of the series, we will look at Job Processing with DataBricks.
References: