Challenge Overview
Match Forum: https://apps.topcoder.com/forums/?module=ThreadList&forumID=722314
Prizes
It's the month of love and we will be awarding prizes to the members in this match $200, $150, $50 for the first three positions and then $50 for 4 random participants who get a better score than the sample submission. (hmehta's) score on the leaderboardImportant Links
- Submission-Review You can find your submissions artifacts here. Artifacts will contain output.txt's for both example test cases and provisional test cases with stdout/stderr and individual test case scores.
- Other Details For other details like Processing Server Specifications, Submission Queue, Example Test Cases Execution
- Sample Submissions/ Tester / Source Files are now also available in the Download Section on the top right. This section will only be visible once you have registered for the match.
Problem Statement
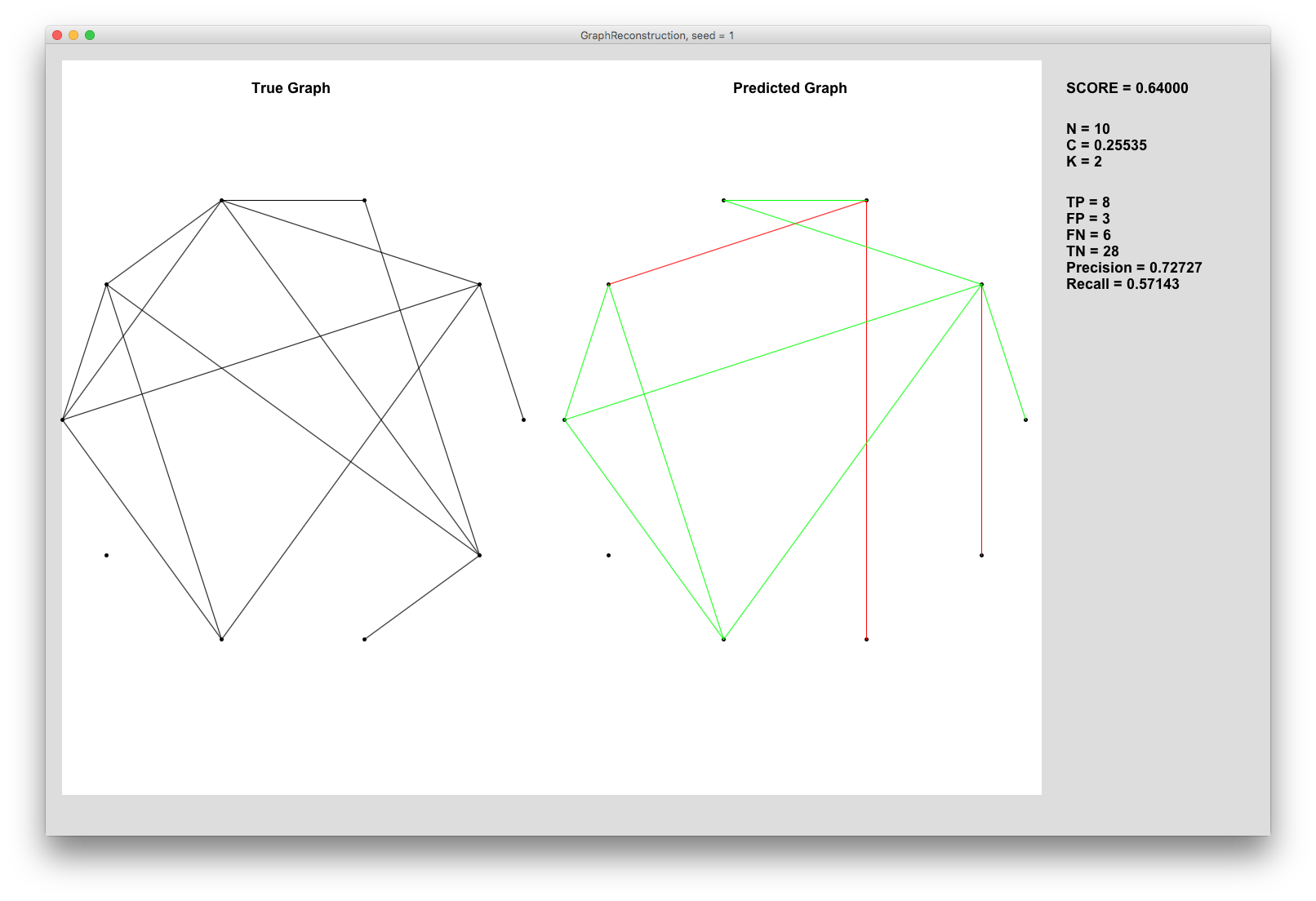
Your task is to reconstruct the structure of a N node undirected graph using some knowledge about its connectivity. In particular you will be given a list of paths, where each path describes the shortest distance (number of hops) between two nodes of the graph. You need to use this information to predict the graph's adjacency matrix. Your prediction's quality will be measured using the F1 score (see Scoring section).Here is an example solution for seed=1, N=10, C=0.25535 and K=2. The graph on the left is the true graph, while the graph on the right is the predicted graph. Edges that match are shown in green, while those that differ are shown in red. The nodes are arranged in a clockwise order with the right-most node having id=0. This solution has a precision of 0.727 (8 edges correct from 11 predicted) and a recall of 0.571 (8 edges from 14 found), so it obtains an F1 score of 0.64 (see Scoring section).
Implementation
Your code will receive as input the following values, each on a separate line:- N, the number of nodes.
- C, the probability that any two nodes of the true graph are connected.
- K, the minimum number of occurences of each node in paths.
- P, the number of elements in paths.
- P lines representing paths. Each line describes a single path formatted as "start end distance", where "start" is the id of the first node, "end" is the id of the second node and "distance" is the shortest distance (number of hops) between these two nodes. If there is no path between the two nodes then "distance" will be -1.
- On the first line, the number N.
- N lines, where the i-th character of the k-th line describes the connectivity between nodes i and k. This character is '1' if the nodes are connected and '0' otherwise. Importantly this character should be the same as the k-th character of the i-th line (symmetric adjacency matrix).
Scoring
Your raw score for a test case is computed using the F1 score = (2 * precision * recall) / (precision + recall). Precision is the percentage of correct edges you found from all the predicted edges. Recall is the percentage of correct edges you found from all the true edges. A perfect solution that finds all the true edges without generating any false edges has an F1 score of 1. If your return was invalid then your raw score on this test case will be -1. Possible reasons include:- Producing an adjacency matrix that does not have N rows and N columns.
- Producing a non-symmetric adjacency matrix.
- Using characters that are different to '0' or '1'.
Test Case Generation
Please look at the visualizer's source code for the exact details about test case generation. Each test case is generated as follows:- Generate the number of nodes N, randomly chosen between 10 and 100, inclusive.
- Generate the connectivity of the graph C, randomly chosen between 1.0/N and 3.0/N, inclusive.
- Generate K, randomly chosen between 1 and 10, inclusive.
- Generate the true graph. Every pair of nodes are connected with probability C.
- Generate the paths. For each path randomly select a pair of nodes which hasn't been used before. Continue generating paths until every node has been selected in at least K paths.
Notes
- The time limit is 10 seconds per test case (this includes only the time spent in your code). The memory limit is 1024 megabytes.
- The compilation time limit is 30 seconds.
- There are 10 example test cases and 100 full submission (provisional) test cases. There will be 5000 test cases in the final testing.
- The match is rated.
Languages Supported
C#, Java, C++ and Python
Submission Format
Your submission must be a single ZIP file not larger than 500 MB, with your Source Code only:
Please Note: Please zip only the file. Do not put it inside a folder before zipping, you should directly zip the file.
- Java Source Code - GraphReconstruction.java
- C++ Source Code - GraphReconstruction.cpp
- Python3.6 Source Code - GraphReconstruction.py
- C# Source Code - GraphReconstruction.cs
SAMPLE SUBMISSIONS
Example solutions for different languages, modified to be executed with the visualizer. You may modify and submit these example solutions.- Java
- Python
- CPP
- C#
Tools
Submission format and an offline tester are available below. You can use it to test/debug your solution locally. You can also check its source code for an exact implementation of test case generation and score calculation. You can also find links to useful information and sample solutions in several languages.DOWNLOADS
HELPFUL INFORMATION
- Marathons Cheatsheet (a collection of useful links)
- Topcoder Cookbook on GitHub
- Topcoder Cookbook forums
OFFLINE TESTER / VISUALIZER
In order to use the offline tester/visualizer tool for testing your solution locally, you'll have to modify your solution by adding the main method that interacts with the tester/visualizer via reading data from standard input and writing data to standard output.Here are example solutions for different languages, modified to be executed with the visualizer. (You will have access to the files, once you register for the match)
- GraphReconstruction.java
- GraphReconstruction.cpp
- GraphReconstruction.py
- GraphReconstruction.cs
- You may modify and submit these example solutions. You will have access to the files, once you register for the match.
java -jar tester.jar -exec "<command>" -seed <seed>
Here, <command> is the command to execute your program, and <seed> is seed for test case generation. If your compiled solution is an executable file, the command will be the full path to it, for example, "C:\TopCoder\solution.exe" or "~/topcoder/solution". In case your compiled solution is to be run with the help of an interpreter, for example, if you program in Java, the command will be something like "java -cp C:\TopCoder Solution".
Additionally, you can use the following options:- -novis. To turn off visualization.
- -seed <seed>. Sets the seed used for test case generation, default is seed 1.
- -debug. Print debug information.