February 3, 2021
Understanding Random Forest and Hyper Parameter Tuning

DURATION
10mincategories
Tags
share

There has always been a war for classification algorithms. Logistic regression, decision trees, random forest, SVM, and the list goes on. Though logistic regression has been widely used, let’s understand random forests and where/where not to apply.
We will discuss a bit about:
Decision trees
Random forest
Hyper parameters
Evaluation
Example
Decision trees
A decision tree is a step by step diagram representing the flow of variables (with their conditions) to conclude a decision, hence the name decision tree.
An internal node shows a condition on an attribute, and a branch serves as the conclusion of the check. Leaf nodes represent a class label. Below is a diagram to understand the basic structure of a decision tree.
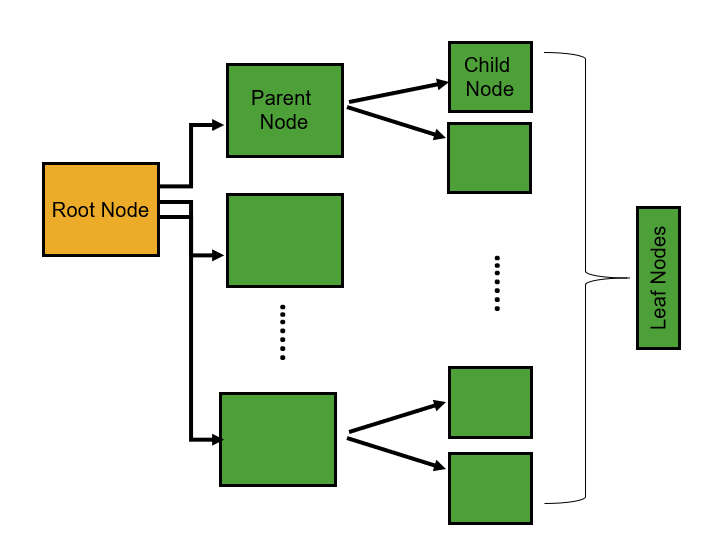
Decision trees can be adjusted to both regression and classification.
Some measures for evaluating the performance of decision trees are:
Gini coefficient
Entropy
Information gain
Though the detailed meaning of these indices is a topic of separate discussion, it is sufficient to know they measure the purity or impurity of a node and evaluate which node will give us the best spilt. By best, we mean a split which will lead to a shorter tree.
Node splitting is a major factor. Simply put, a decision tree makes decisions by splitting nodes into sub-nodes. This process is performed several times during the training algorithm leading to decision trees performing well.
Node splitting, or simply splitting, is the process of dividing a node into multiple sub-nodes to create relatively pure nodes.
Before moving on to random forest, we need to understand a few more concepts and disadvantages of decision trees, i.e., why do we need random forest?
While decision trees have advantages like the fact that non- linear relationships between the variables do not influence tree performance, they are visually attractive, easy to understand and explain, and they require little data preparation, they do have certain disadvantages.
Major drawbacks of decision trees:
Not as high level of accuracy for real life data
Overfitting/underfitting due to depth of tree
Decision trees contain high variance
With high variance comes the concept of bagging.
Bagging
Bagging (bootstrap aggregation) is a procedure used to decrease the variance of the machine learning method.
The first step is to build several subsets of data from the training sample chosen at random with replacement, resulting in an ensemble of different models. Finally, the mean of predictions from different trees are considered. Remember that bagging takes all the features at every iteration.
Now let’s talk about random forest.
Random forest
Random forest is an extension of bagging, but taking one extra step. Along with taking the random subset of data, it also takes the random selection of features rather than using all features to grow trees. When you have many decision trees, it becomes a random forest
By allowing each tree to randomly sample from the dataset with replacement we get different trees since decision trees are sensitive to data they are trained on.
Decorrelation of trees
A random sample of m predictors is taken to split nodes from the full set of p predictors each time a split in a tree is considered.
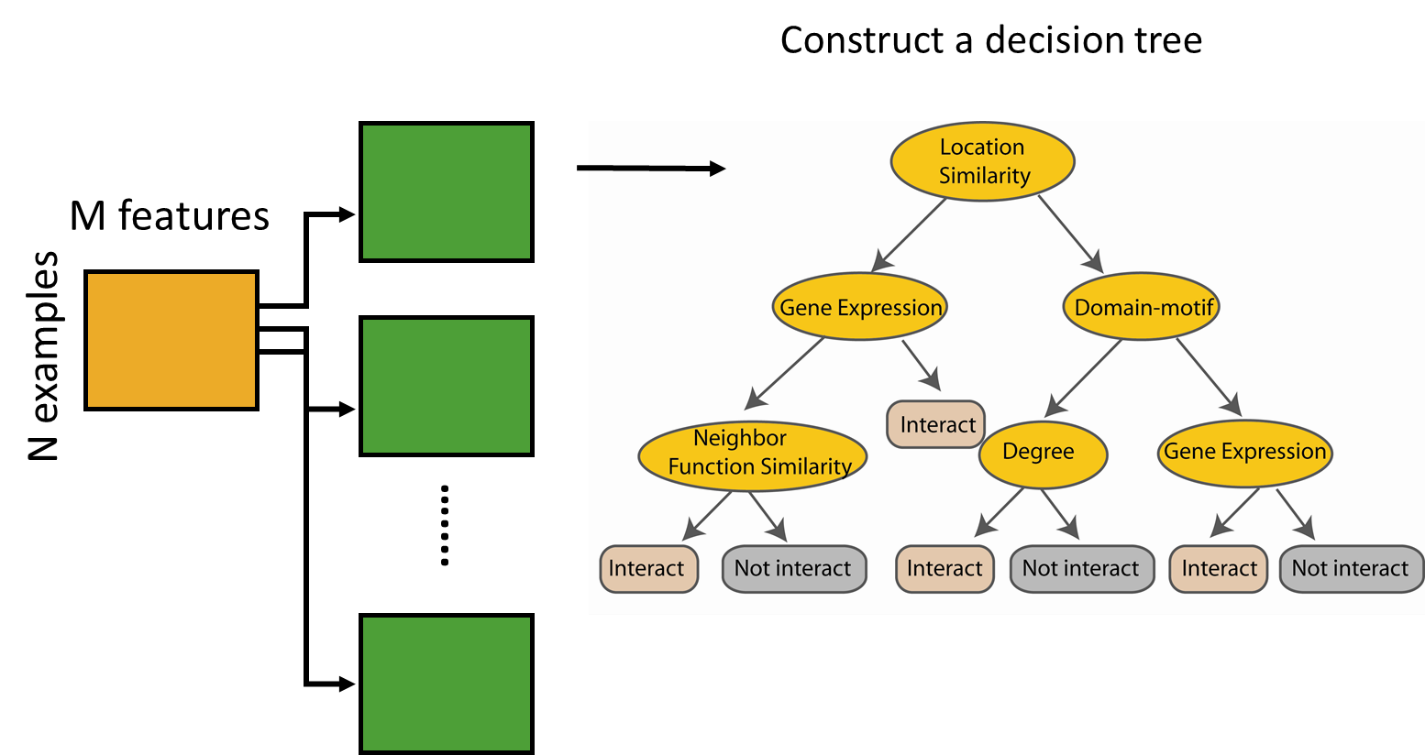
Note - In choosing the split feature at each node choose only among m<M features
Create decision tree from each bootstrap sample
Take the majority vote

Random forest has many pros including accuracy, efficient runs on large databases, a large number of variables can be handled, it provides variable importance, missing data can be estimated, and accuracy is maintained when data is missing
Cons of random forest include occasional overfitting of data and biases over categorical variables with more levels.
Hyper parameters
A parameter of a model that is set before the start of the learning process is a hyperparameter. They can be adjusted manually.
Most used hyperparameters include
Number of trees
Maximum depth of each tree
Bootstrap method (sampling with/without replacement)
Minimum data point needed to split at nodes, etc.
Validation curves and exhaustive grid search are the two techniques most commonly used to choose which hyperparameters to adjust. Validation curves visually check for potential values of hyperparameters which can be optimized. Exhaustive grid search tries every single possible combination of the hyperparameters. Remember when building validation curves, the other parameters should be held at their default values.
Pros of adjusting hyperparameters
Adjusting hyperparameters improves accuracy of the model
Not adjusting the size of the trees (e.g. max_depth, min_samples_leaf, etc.) leads to fully grown and unpruned trees which can be very large on some data sets.
Adjusting the size and complexity of the trees helps in reducing memory consumption.
Example
Finally, to get a real-life sense of decision trees let us look at an example. We’ll load some fake data on past hires.
As this tutorial focuses on understanding the theory, we won’t go into coding.
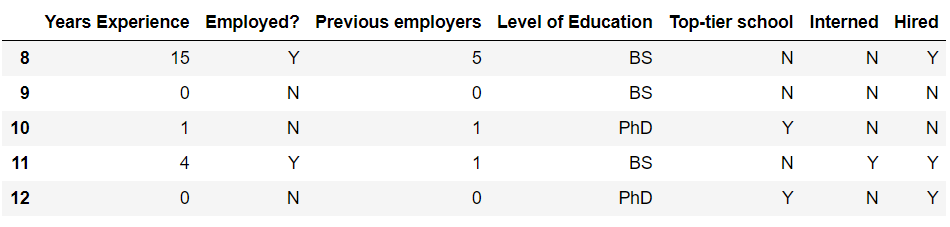
Map Y,N to 1,0 and levels of education to some scale of 0-2 as scikit-learn needs everything to be numerical for decision trees to work.
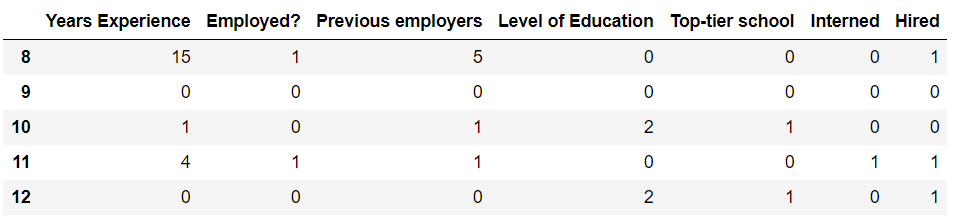
After separating features from the target variable (“Hired” here) we can simply call and fit decision trees in Python.
As simple as that!
Using pydotplus library to display the decision tree:
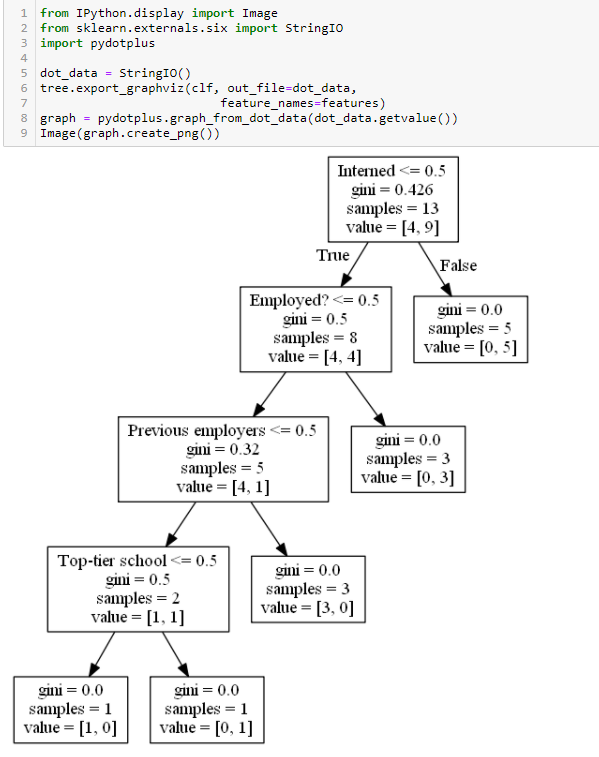
To read this decision tree, each condition branches left for “true” and right for “false”. When you end up at a value, the value array represents how many samples exist in each target value.
So, value = [0. 5.] means there are 0 “no hires” and 5 “hires” by the time we get to that node. And value = [3. 0.] means 3 no-hires and 0 hires.
Hopefully we clarified decision trees and random forests for you. Keep reading more tutorials for a better understanding.