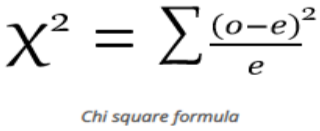September 15, 2021
Statistics and Hypothesis Testing


Data science, or data analysis, is one of the most useful things in this modern age. It is used in a variety of domains, like business, medical science, and defense. Our brains collect data from nature and try to analyze patterns using logic and our strong computational neural network. Likewise, in data science we make mathematical and statistical concepts and try to find patterns in data. As we know, statistics is all about what the data means and analyzing data. Trying to save useful information from data hypothesis testing is the most important part of extracting information from the data.
Hypothesis
The basic and conceptual definition of hypothesis is: hypothesis is a guess made for any decision. After making our guess we try to test whether it is true or false on the basis of some experiment and observation.
Hypothesis Statements
When we are going to enact any decision, we make some conditional statements like If “……” then “…….”.
Before making any hypothesis keep in mind that a good hypothesis will contain an “if __ then__” condition, for example:
If (statement1), then (statement2). Both statement1 and statement2 can be dependent and independent events.
Both statement1 and statement2 can be tested in some scientific, mathematical, or domain knowledge-based experiments.
Before moving forward to hypothesis testing we will learn about the confidence interval and p-value.
Confidence Interval
Sometimes we do not have the proper information about population data but we want some estimation. In that case we generally take a sample from the population and perform a computation. Then, on the basis of the sample estimation, we conclude a population estimation. There are two types of estimation:
Point estimation
Interval estimation
Point estimation: Here we estimate our population on the basis of a single numerical value, like mean of population= mean of sample.
Interval estimation: Interval estimate concludes the result of a population on the basis of some interval. Here, rather than conclude with a single digit, we give a range of conclusion. There will be a lower confidence interval and an upper confidence interval.
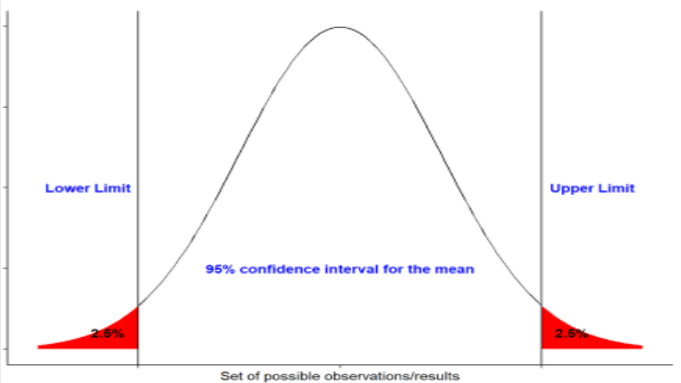
Confidence interval is made of two elements: point estimation and marginal error.
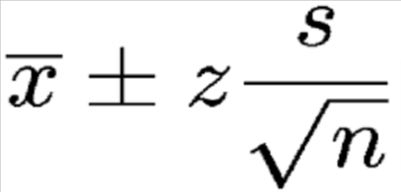
Above, the x component is sample mean, z is confidence. For the z score we generally take 95%. S is the standard deviation of population and n is sample size.
P value:
There is a simple definition of p value: it is the probability of null hypothesis to be true. The term “null hypothesis” we will see later. P value can also be called significance value. Although there is no hard and fast rule for p value, we generally take p<=0.05. This means we conclude our null hypothesis is true if p value is less than 5%. Below is the range of p values.
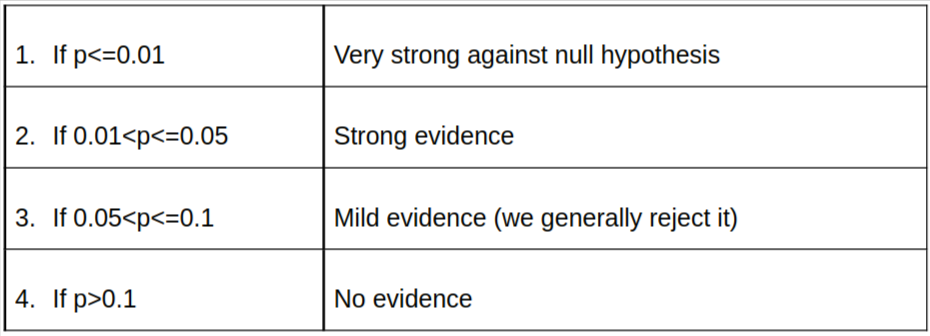
Now we will move on to hypothesis testing.
Hypothesis Testing:
Hypothesis testing is a way to test the assumptions we made on a survey or evaluate our statement on the basis of some evidence. Above we saw the definition of hypothesis. Here we see all the procedures and types of testing of hypothesis statements. There are two types of hypothesis: null hypothesis and alternate hypothesis.
Null Hypothesis:
Null hypothesis is accepted evidence or default evidence that treats everything similar or equal, like given assumptions that everyone has. For example, that the earth is round, sea-water is salty, etc.
Alternate Hypothesis:
This is opposite of null hypothesis. This is also called research hypothesis or to be claimed hypothesis. Below is a pictorial representation of when we will take a null hypothesis to be true and when we will take an alternate hypothesis to be true.

Steps to perform hypothesis testing:
Make the initial assumptions
Collect the data (evidence)
Define the level of significance
Gather the evidence (either accept or reject it).
Below is flow graph for hypothesis testing: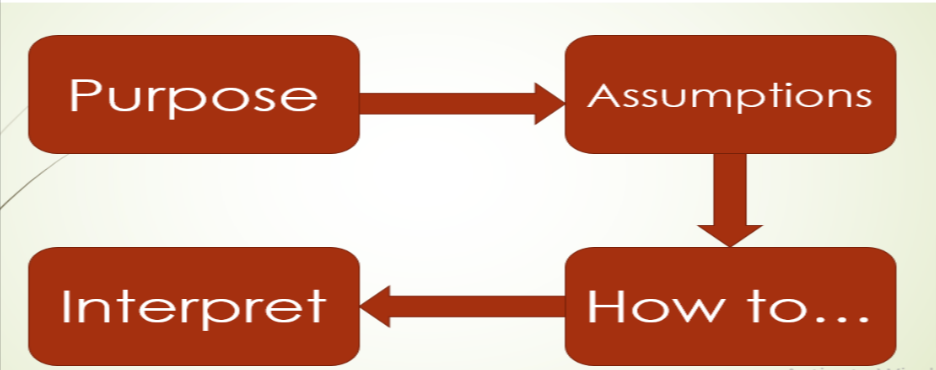
Now we will discuss types of hypothesis testing. On the sample type and sample classes there are many types of hypothesis testing like t-test, z-test, chi-square test, and Anova test. There are some commonality points to describe when which testing type should be used.
When there are two samples, one categorical and other continuous, then we will use t-test. When the number of classes in a sample is greater than 2 then we will use the Anova test.
When there are two samples and both are categorical, then we will use the chi-square test.
When both are continuous then we will use correlation. This we will see in the next article.
When one is continuous and the outcome is categorical then this is a classification problem.
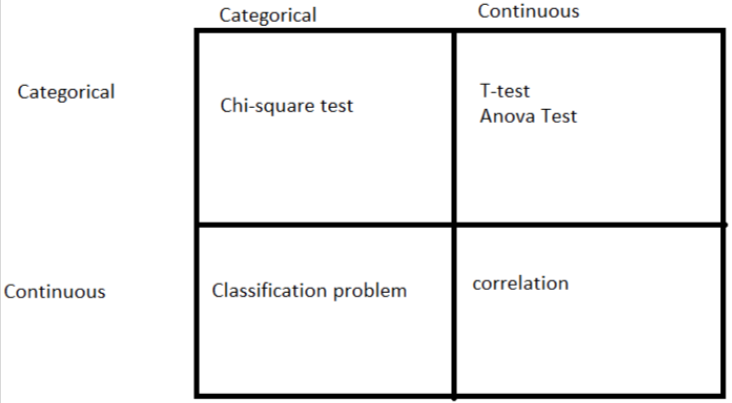
Now we will see details of all the tests below.
T-Test
A t-test is a type of inferential statistic which is used to determine if there is a significant difference between the means of two groups, which may be related in certain features.
The t-test has three types:
1. One-sample t-test
2. Two-sample t-test
3. Relative test
1
2
3
4
5
6
7
8
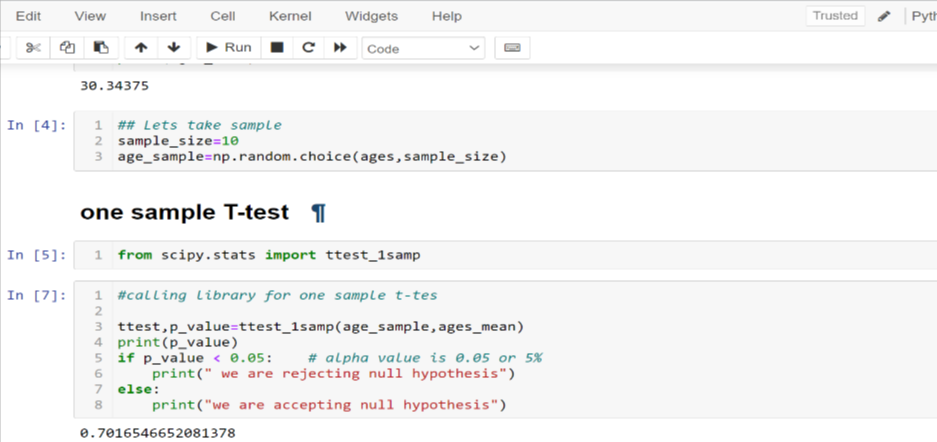
#calling library
for one sample t - test
ttest, p_value = ttest_1samp(age_sample, ages_mean)
print(p_value)
if p_value < 0.05: # alpha value is 0.05 or 5 %
print(" we are rejecting null hypothesis")
else:
print("we are accepting null hypothesis")
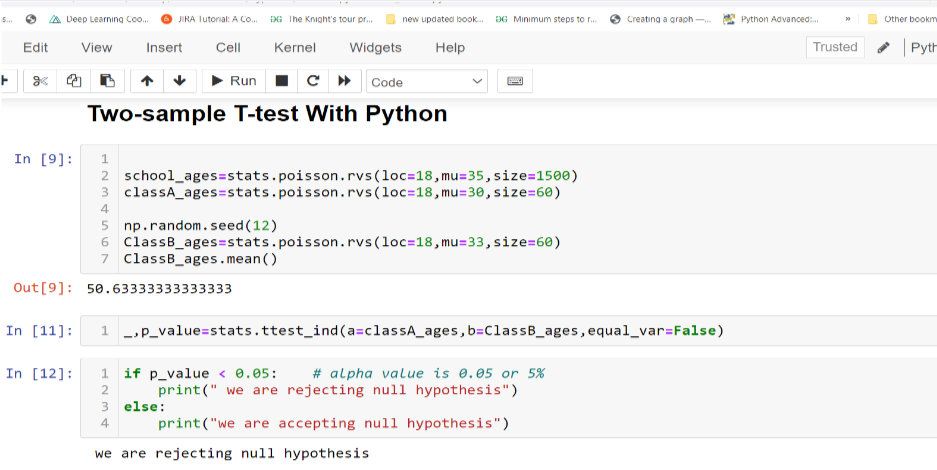
Two-Sample T-Test With Python
The independent samples t-test, or two-sample t-test, compares the means of two independent groups in order to determine whether there is statistical evidence that the associated population means are significantly different. The independent samples t-test is a parametric test. This test is also known as an independent t-test.