February 2, 2021
PYTHON FOR DATA ANALYSIS AND MANIPULATION: PANDAS

DURATION
15mincategories
Tags
share

Pandas is an open source library. It uses the power and speed of NumPy to make data analysis and preprocessing easy for data scientists. It offers rich and highly strong data operations. Learn more about NumPy here.
INSTALLATION PYTHON (3.X)
Create a directory on the desired location and name it.
Open the folder and press ctrl+right click and click on open powershell/terminal window here.
Inside powershell / terminal window type:
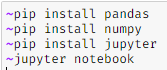
This will open the browser with the following interface.
Click on new in the top left and select Python 3 (Python 3 must be installed on the system).

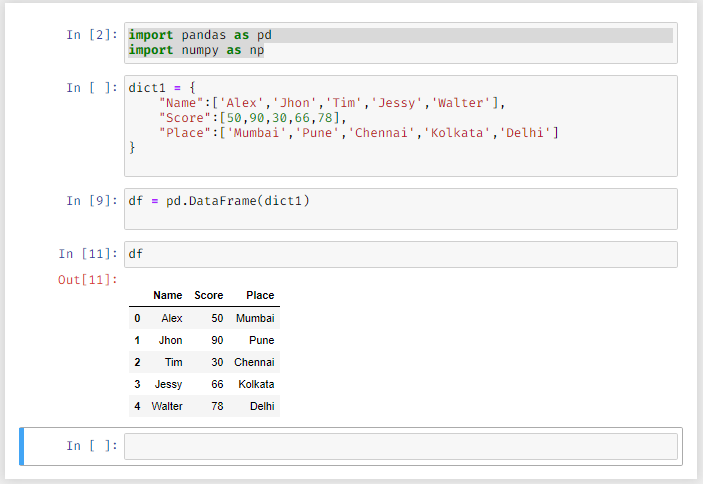
CREATING A DATAFRAME:
Using Dictionary:
A dataframe is a data structure with rows and columns, it can also be imagined as a spreadsheet or a SQL table or a series of objects.
Import Pandas as pd.
Create a dictionary .
To create a dataframe we use
Pd.dataframe(‘dictionary_name’) or pandas.dataframe(‘dictionary_name’)
and store it in the variable.
This will create the dataframe of the dictionary given.
Print the variable using the print function.
In Jupyter use enter to go to a new line and shift+enter to execute the lines above it.
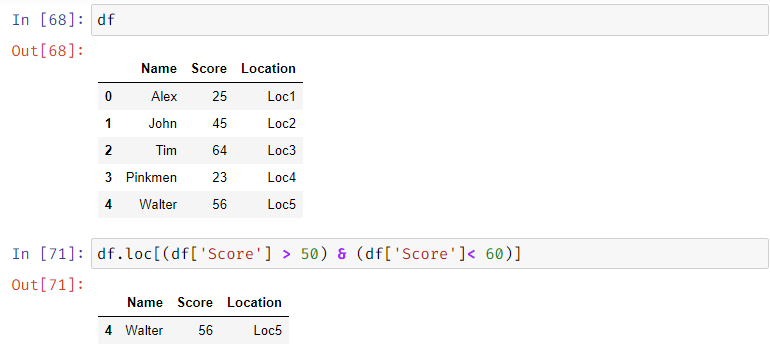
FUNCTIONS OF DATAFRAMES
ALL THE FUNCTIONS ARE PERFORMED ON THE FOLLOWING DATAFRAME:
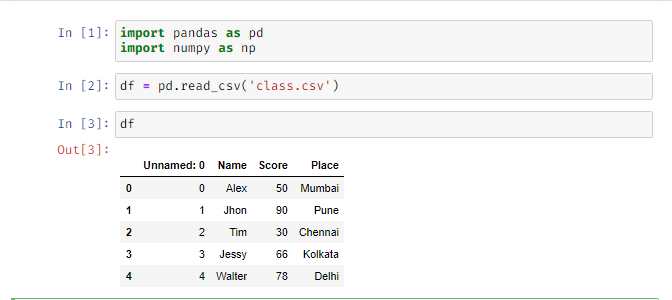
Converting to CSV: We can also convert the dataframe to a CSV (Comma Separated Value) / excel sheet using: df_name.to_csv(‘csv_filename’). This will create an excel sheet in the same directory where we installed Pandas.
Reading a CSV: Using df.read_csv(‘CSV file name’) we can access CSV files.
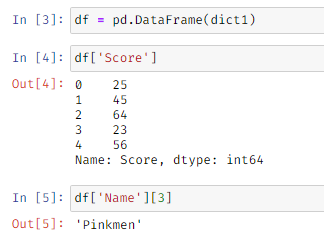
Display a particular column: Using df_name[‘column_name’] we can display a particular column.
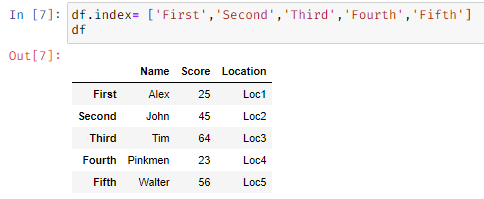
Custom indexing: We can provide customised index to the column using
Df_name.index = [‘Array of indexes’]
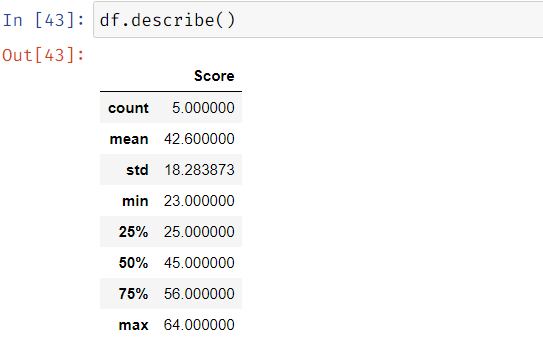
Statistical measurements: We can get statistical measurements of the data using df_name.describe() function:
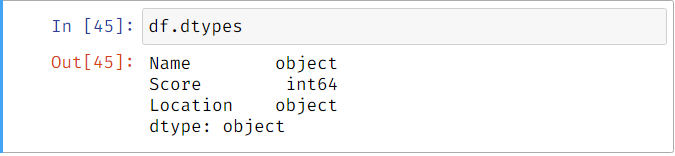
Data-type of the columns: We can check the data-type of each column using
Df_name.dtype
Getting the number of indexes and columns: Using df_name.index and df_name.columns we can get details about the indexes and columns.

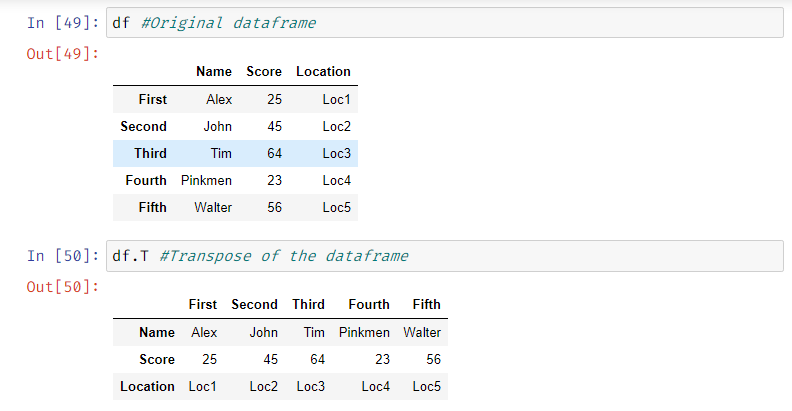
Transpose of the dataframe: We can transpose the dataframe, i.e., change the rows to columns and vice-versa.
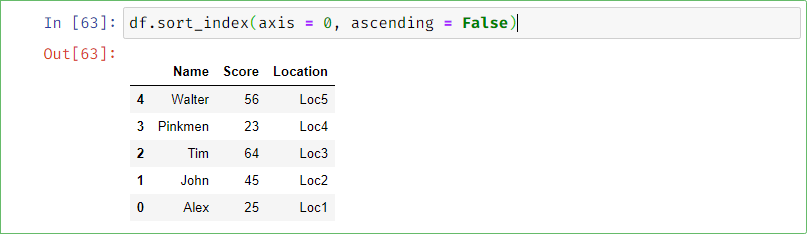
Sorting the dataframe: We can sort the dataframe using
Df_name.sort_index(axis = 0/1 , ascending = True/ False). 0 axis is used to sort with respect to row and axis equal to 1 is used to sort the dataframe according to column. True and false ascending is used to sort the dataframe in ascending order or descending order respectively.
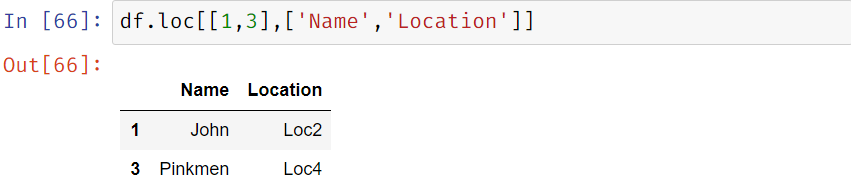
Display selective rows and columns: we can display custom rows and columns using
Df_name.loc[[from_row, to_row], [from_column, to_column]]]
Passing queries to the data frame: queries can be made to dataframe, including complex queries in the following way:
Df_name.loc[(query 1),(query 2),(query 3), . . . . . . .].
Getting value at a particular location: Using df_name.iloc[row, column] we can extract value at a particular location.

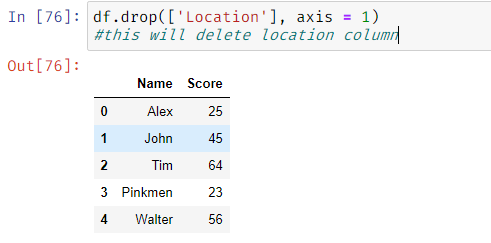
Deleting a row or a column: Using df_name.drop([‘column/ row name’],axis = 0 / 1),
axis 0 is used to delete a row and axis 1 is used to delete a column.
Setting data to none and checking for it is null: To convert a whole column to null we can change it using df_name[‘col_name’] = None. To check if the values are null or not we use df_name.isnull()
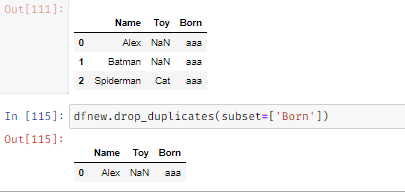
Delete the duplicate values: We can delete duplicate values using df_name.drop_dupolicates(subset = [‘col_name’])
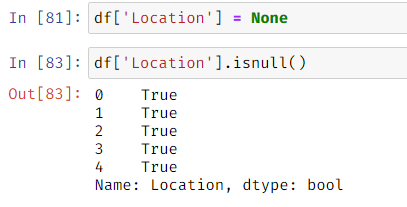
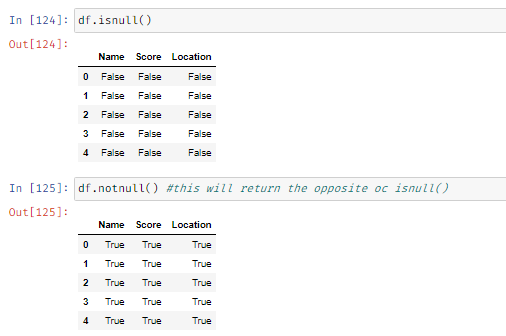
Checking if the values are null or not null: This can be fetched using df_name.isnull() and df_name.notnull() methods which returns a dataframe with Boolean values.
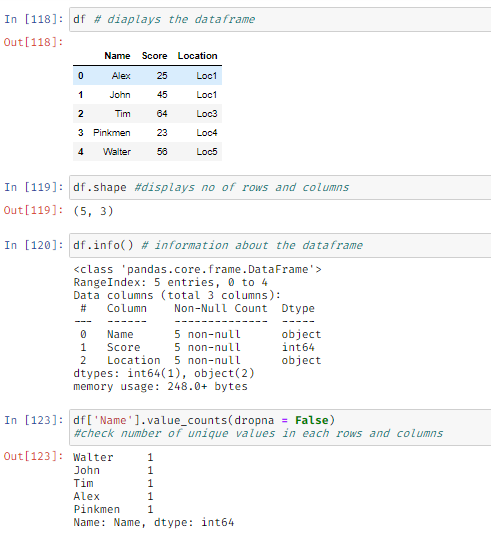
Extracting information about the dataframe: Information such as shape or unique values can be extracted using the following methods:
TRY IT YOURSELF:
Create a dataframe which contains only integers with three rows and two columns and run the following dataframe methods on them:
Df.describe()
Df.mean()
Df.corr()
Df.count()
Df.max()
Df.min()
Df.median()
Df.std()
USES OF PANDAS LIBRARY FOR DEVELOPERS
Data representation: Pandas provides a very efficient way to represent data which makes it easier to analyse and understand.
More work in less code: This is one of the best advantages of the Pandas library. The tasks which would normally take multiple lines of code can be executed with Pandas in one to two lines of code.
More Features: Pandas are very powerful. They provide a huge set of important commands which are used to easily analyze and manipulate data. Pandas can perform various tasks like filtering, segmenting and segregating the data according to our preference.
Efficiently handles large data: Pandas helps to save a lot of time by importing large amounts of data very fast.
Makes data flexible and customizable: It has a lot of features which helps us to customize, edit and pivot the data according to our own requirements. It helps to extract the most out of the data.