May 20, 2010
SRM 470

DURATION
25 mincategories
Tags
share

Match Summary
Round Overview
Discuss this match
This SRM, sponsored by Yandex, attracted 1757 competitors. Most of the problems had multiple solutions, the Div1-250/Div2-500 being the one with the largest number of variety. The divison 1 problems proved to be pretty challenging, nobody managed to solved the Div1-1000 and the success rate for the Div1-250 was not very high, despite having strong sample cases. Despite having trouble in the Div1-250, neal_wu managed to become the Champion, thanks to a challenge and his fastest submission for the Div1-500 problem. rng_58 and ploh finished second and third, respectively. wata was the only competitor to submit all three problems. Unfortunately, his Div1-1000 didn’t pass the system test.
In division 2, coders were given problems that require analysis. The easy problem was solved by the majority of the contestants, and for the medium problem they had the Div1-250. Contrast to division 1, the Div2-1000 problem was rather easy with 62 successful submissions.
LinearTravellingSalesman
Problem Details
Used as: Division Two - Level One:
| Value | 250 |
| Submission Rate | 878 / 1015 (86.50%) |
| Success Rate | 741 / 878 (84.40%) |
| High Score | topcoder.7 for 249.95 points (0 mins 25 secs) |
| Average Score | 200.71 (for 741 correct submissions) |
The statement states that there exists a line which passes through all the cities. Consider the cities in order by traversing this line, denoted by {x1, x2, … xn} in the order they are visited. The key observation is that by visiting cities in this order (or in its reverse order), the total distance travelled, which is equal to the Manhattan Distance between x1 and xn, is minimum. This is true since in any solution, both cities x1 and xn are included and hence, the total distance is bounded below by the Manhattan Distance between them.
All that’s left is to compute the distance travelled. Consult forifchen’s solution for a very short and elegant approach.
Used as: Division Two - Level Two:
| Value | 500 |
| Submission Rate | 227 / 1015 (22.36%) |
| Success Rate | 108 / 227 (47.58%) |
| High Score | hinai for 384.51 points (16 mins 39 secs) |
| Average Score | 242.78 (for 108 correct submissions) |
Used as: Division One - Level One:
| Value | 250 |
| Submission Rate | 599 / 742 (80.73%) |
| Success Rate | 461 / 599 (76.96%) |
| High Score | sandro_barna for 224.98 points (9 mins 41 secs) |
| Average Score | 139.10 (for 461 correct submissions) |
This problem turns out to be pretty challenging and time-consuming. It can be solved with several approaches.
Game Theory + Dynamic Programming
This solution tries to determine the outcome of every state, where each state is a set of colors that have been chosen. Observe that the number of colors chosen is equal to the number of turns. For each state, there are 3 possibilities of return values :
Draw - The game ends in a draw.
Win X - The next player to choose a color wins the game within X turns.
Lose X - The other player wins the game within X turns.
For each state, we follow the following procedure :
If in current state only one player reaches the trophy room, that player wins the game in 0 turns.
If both players can reach the trophy room, the game ends in a draw.
Otherwise, we make the current player to try each color, and determine the outcome for each color recursively (i.e., the current bitmask + the color chosen). Among all of these outcomes, pick the one according to the priority below :
Pick the one that returns Lose X with the smallest value of X. Return Win X+1.
Otherwise, pick the one that returns Draw. Return Draw.
Otherwise, pick Win X with the biggest value of X. Return Lose X+1.
For those infamiliar with the priorities above, you could consult this excellent tutorial about Game Theory.
To allow the solution to run within the time limit, we need to memoize the answers for each state. The overall running time of this solution is then N * 2N, where N is the number of colors (i.e., 16). Consult SergeiRogulenko’s solution for an in-contest implementation.
Greedy + Simulation
This solution, together with the Dynamic Programming approach above, are the two most common solutions in the contest.
Suppose the trophy is in room X. John will win when all the doors to the left of room X are opened, while Gogo will win when all the doors to the right of room X are opened. Let’s call the set of colors that need to be chosen in order for John to win as JohnColor. In similar fashion, we define GogoColor.
We now define JohnUnique to be the colors in JohnColor but not in GogoColor. GogoUnique is defined similarly. Finally, BothColor are the set of colors that are present in both JohnColor and GogoColor. In the algorithm below, we will subtract a color from a set if it has been chosen. Hence, John will be able to reach the trophy room if both JohnUnique and BothColor are empty. Similarly, Gogo will be able to reach the trophy room if both GogoUnique and BothColor are empty.
Each turn, the greedy approach works as follow:
If JohnUnique is not empty, John chooses one of such color. Otherwise, he chooses one among BothColor.
increase the number of turns
checkState
If GogoUnique is not empty, Gogo chooses one of such color. Otherwise, he chooses one among BothColor.
increase the number of turns
checkState
checkState checks the current state to determine whether there is a winner, or a draw is achieved. If an outcome is achieved, checkState will return the corresponding return value.
To see why this is correct, we will see that in these cases:
John wins
Gogo wins
The players are simulated to play with the desired strategy. Observe that in other cases, the game is a draw.
Suppose John will win the game. The observations are:
All the colors in JohnUnique and BothColor will be chosen by John.
Gogo will always be able to stall him by choosing colors from GogoUnique. Furthermore GogoUnique will not be empty during the end of the game.
To see this, suppose GogoUnique is empty. For John to win, it’s necessary that BothColor is empty at the final state. However, at this moment, Gogo will also be able to reach the trophy room (since both GogoUnique and Bothcolor are empty), which is a contradiction. Furthermore, since Gogo won’t be able to finish choosing the colors in GogoUnique before John finishes choosing all colors he needs to win, Gogo can’t win and so he will try to make the game last longest by not helping John. The case where Gogo wins is handled similarly.
It is now easy to see that the greedy approach simulates these cases. In other cases, observe that both GogoUnique and JohnUnique will be empty before BothColor is empty. Hence, by the time BothColor is empty, the game will end in a draw, as desired.
You can consult ploh’s solution for an in-contest implementation.
Analysis
Continuing from the previous section, we have observed that for a player (suppose it’s John) to be able to win, Gogo must be able to stall by choosing colors from GogoUnique. This statement is equivalent to: For John to be able to win, JohnUnique + BothColor <= GogoUnique (since John gets the first turn). We will now see that this condition is actually sufficient and necessary for John to win. The ‘necessary’ part is taken care of in the previous section. To see that this condition is sufficient, observe that when JohnUnique + BothColor <= GogoUnique, by calling all the colors in JohnUnique + BothColor, John will be able to win since Gogo would not be able to call all the colors in GogoUnique in time.
By similar reasoning, we can deduce that For Gogo to win, GogoUnique + BothColor < JohnUnique.
Armed with these two powerful observations, a simple algorithm is obtained:
1
2
3
4
5
6
7
8
9
10
if (JohnUnique + BothColor <= GogoUnique)
//Gogo will always choose a color not in JohnUnique and BothColor to make the game lasts longest.
return (JohnUnique + BothColor) * 2 - 1
if (GogoUnique + BothColor < JohnUnique)
//John will always choose a color not in GogoUnique and BothColor to make the game lasts longest.
return -(GogoUnique + BothColor) * 2
//If both player can't win, the game ends in a draw
return 0
Consult rizar’s solution for an in-contest implementation.
Conclusion
The three approaches can be summarized as follows :
| Approach | Code Length | Idea | Reliability |
| Dynamic Programming | Long | Easy | Safe |
| Simulation | Medium | Medium | Risky |
| Analysis | Short | Difficult | Somewhat Safe |
Used as: Division Two - Level Three:
| Value | 1000 |
| Submission Rate | 101 / 1015 (9.95%) |
| Success Rate | 62 / 101 (61.39%) |
| High Score | mbr1 for 873.70 points (11 mins 8 secs) |
| Average Score | 577.43 (for 62 correct submissions) |
This problem is significantly easier than the usual divII-1000 problem, even to the point that some of us think that the divII-500 pointer is harder :).
Consider each cell as a vertex, and edges exist between two adjacent cells. The weight of an edge is the absolute difference between the number in the two adjacent cells. The problem is then reduced to finding the maximum spanning tree in the graph.
Okay, I know this is all too sudden, so let me explain.
First, we will see that the optimal solution can be represented by a spanning tree in the graph above. Consider an optimal solution A. Let G be a graph initially consiting of vertexes and no edges. For each pair of cells chosen to construct this solution, add a corresponding edge in G. To see that G forms a spanning tree, or simply, a tree, first observe that we add edges (row*column)-1 times, or |V|-1 times. Next, observe that there’s not cycle in this graph (since if it exists, then we would have made an improper step in choosing the adjacent cells, that is, we choose two activated cells instead of one activated, one non-activated). Hence, G is a tree.
Constructing a solution from a tree is simple. We start at the vertex representing cell (0,0), and apply DFS. Observe that since all vertices are visited once, this corresponds to a solution.
Hence, since the score corresponds to the sum of the weights of the trees, the optimal solution must have the maximal sum of the weights of the tree. Hence, this problem asks us to find a maximum spanning tree in the graph. Most solutions are based upon Prim’s Algorithm, that is, in each step they greedily activate the cell that would result in a maximum possible score increase. Consult mbr1’s solution for a clean in-contest implementation.
Used as: Division One - Level Two:
| Value | 500 |
| Submission Rate | 159 / 742 (21.43%) |
| Success Rate | 111 / 159 (69.81%) |
| High Score | neal_wu for 464.04 points (8 mins 2 secs) |
| Average Score | 298.90 (for 111 correct submissions) |
Notations :
Let M be the number of segments that Little John has drawn, and let N be the number of dots.
This problem relies on the theory of random variables and expectations. You may wish to consult this, specially in the mathematical definition section.
The problem asks for the expected number of distinct pairs of line segments that cross each other in the final drawing. The key to solve this problem is to see that this answer is equal to the sum of E(x,y) for each pair of dots {x,y} in the top edge of the rectangle, where E(A,B) is the expected number of crossing pair of segments originating from A and B, which is equal to the probability for the line segments originating from dot A and dot B to cross each other. That is :
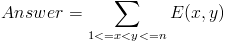
This is the favorite method used by most competitors in the contest. Let us denote the dots as empty dots (dots that haven’t been chosen by Little John) and drawn dots (those that have been chosen by Little John). Initially, the answer is set to 0. The idea is that the formula above can be broken down into three types of dots :
Two drawn dots - Brute force over all M*M/2 pairs of drawn dots, and count the number of crossing pairs. Simply add this number to the answer.
Two empty dots - Observe that for each pair of empty dots, the probability that the segments originating from these two dots to cross each other is exactly 0.5. The number of such pair is ((N-M)(N-M-1)2). Hence, the amount that this portion contributes for the answer is : ((N-M)(N-M-1)2) * 0.5 = ((N-M)*(N-M-1)) / 4.
One drawn dot, one empty dot - Iterate over all drawn dots, and for each of these dots, count the expected number of segments that will cross the segment originating from this dot (excluding the ones already calculated by part (1)). This can be done in several ways, one of the simplest is to count 4 variables :
topLeft : the number of empty dots to the left of this drawn dot.
topRight : the number of empty dots to the right of this drawn dot.
bottomLeft : the number of empty dots to the left of the corresponding dot in the bottom side for the drawn dot.
bottomRight : the number of empty dots to the right of the corresponding dot in the bottom side for the drawn dot.And the expected number is : topLeft * bottomRight / (bottomLeft + bottomRight) + topRight * bottomLeft / (bottomLeft + bottomRight).
Finally, return the answer. Consult ainu7’s solutionfor an in-contest implementation.
Alternatively, one can brute force over all n*(n-1) pairs of dots, and add the probability that the two of them will cross each other. Consult RAVEman’s solution for an in-contest implementation.
Used as: Division One - Level Three:
| Value | 1000 |
| Submission Rate | 2 / 742 (0.27%) |
| Success Rate | 0 / 2 (0.00%) |
| High Score | null for null points (NONE) |
| Average Score | No correct submissions |
Notations :
rock(X) : get the rock covering cell X
cost(X) : the cost to destroy rock X
For simplicity, by city_pair we are referring to pair of cities that are denoted by the same character.
Sketch of Idea
The basic idea can be gained by solving an easier version of this problem, where there are only 1 pair of cities. Then, the minimum cost required is equal to the shortest-path distance between them, where cells are vertices and there are two edges between each neighboring cells (one for each direction). An edge (u,v) has weight cost(rock(v)) if u != v and v is part of a rock. All other edges has weight 0.
To solve the original problem, we construct another directed graph G. Each vertex in G corresponds to a block of neighboring empty squares, block of rock, or a city. There are two edges between every pair of vertex if they share a side (as before, one for each direction). The weight of each edge entering vertex u is equal to the cost to destroy rock u (or 0 if u is a city or a block of empty squares).
Now, let’s try to graph a solution in G. The idea is that we construct a road originating from each of the cities, and we are interested only at its other end point. In the initial case, all the roads’ end points are in their respective starting cities . Then, the roads are propagated to other vertexes (and possibly, entering other city). This is done while spending the cost to destroy rocks along the way (which corresponds to the weight of the edges). Two roads may be merged inside the interior of a vertex v1 (in other word, the two roads coincides), but for this, we need to decrement the total cost so far by cost(v1), since v1 is destroyed twice (once for each entering road). For a road to connect a city_pair, the roads originating from both of them must somehow be connected (through merging). In other word, a solution corresponds to forming a subgraph from G, where each city_pair belong to the same connected component (ignoring edge directions).
The following observation is the key to solve this problem:
There exist an optimal solution, where their representation in G forms a forest (omitting directions).
To see this, first note that this is equivalent with saying that there is no cycle in the graph. Suppose there is a cycle in the graph. Then, we can remove any edge in this cycle and all the cities in the resulting graph will still remain connected. Continuing this procedure until all cycles are removed yields a forest with the same connectivity as in the original graph.
In the next section, we will construct a solution based upon these observations.
Solution
First, we compute shortestPath(X,Y): shortest path to go from X to Y in graph G (that is, the cost to build a road from X to Y by destroying all rocks in the way except X). This will be required later in the algorithm.
The solution is to construct a function solve(A,MASK) that does this: given inputs {A,MASK}, where A is a vertex in G and MASK masks cities, it will return the minimum cost required to achieve these:
If only one city from a city_pair is masked to MASK (denote these cities as singular cities), the road originating from that city must be connected to vertex A.
If both cities from a city_pair are masked to MASK (denote these cities as paired cities), the roads originating from those cities are connected.
In other word, we want to find a forest such that all singular cities are connected to the subtree that is connected to A, while all paired cities are somehow connected either in the subtree connected to A or in another subtree that is not connected to A.
Our initial states are : for each city u, let v1 be the corresponding vertex of u. Let m masks only city u. Then, solve(v1,m) = 0. This corresponds to the initial case described in the Sketch of Idea above.
The return value of solve(A,MASK) (denoted by return_value) depends on two subproblems :
for each SUBMASK = subset of MASK && SUBMASK != {}, return_value = min(return_value, solve(A,SUBMASK) + solve(A,MASK - SUBMASK) - cost(A))
for each vertex B, return_value = min(return_value,solve(B,MASK) + shortestPath(B,A))
In (1), we are merging two roads in vertex A. In (2), the roads that have been possibly merged in other vertex are propagated to vertex A. Observe that this algorithm will not yield a forest but a tree (since we always build roads when we go from a vertex to another, regardless of the mask). To make this algorithm yields a forest, (that is, as in the answer), observe that if for all cities masked in MASK, its city pair is also masked in MASK, no city in MASK needs to be connected to vertex A. Hence, we can move at ‘free cost’, since we don’t actually build a road.
Hence, we can construct the solution bottom up with respect to MASK. Refer to the following code :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
for mask = 1 to(1 << ncities) - 1 {
//the (1) part : try to merge two subtrees in every vertex
for i = 0 to | V | {
for j = each possible submask {
solve(i, mask) = min(solve(i, mask), solve(i, j) + solve(i, mask - j) - (isThereLoneCity(j) * isThereLoneCity(mask - j) * cost(i)))
}
}
//the (2) part : try to propagate the road
for i = 0 to | V | {
for j = 0 to | V | {
//isThereLoneCity(MASK) return 0 if all cities masked in MASK have their city pair also masked in MASK, and 1 otherwise
solve(i, mask) = min(solve(i, mask), solve(j, mask) + isThereLoneCity(mask) * shortestPath(j, i))
}
}
}
The answer is then solve(any_vertex,full_mask).
Complexity and Optimization
The complexity of the approach above is 2N * 2N * |V| + 2N * |V| * |V|, where N is the number of cities ans |V| is the number of vertex. Since |V| can be as high as 800, and N as high as 8, the overall complexity is 216268800, which is dominated by the 2N * |V| * |V| part. This complexity can be much lowered by altering the graph G so that each vertex in G corresponds to a rock/city, and the weight(u,v) = shortestPath(u,v). The observation that allow this modification is there exist an optimal solution in which all the roads merge in the interior of a city or a rock (that is, no two roads merge in empty cells). Since the number of rocks is at most 62 and the number of cities is at most 8, the overall complexity becomes 5841920, which is small enough. Further observation can show that the 2N * 2N factor is actually 3N (since we only merge disjoint masks).