
|
Match Editorial |
Tuesday, September 28, 2004
Match summary
Strings, strings, strings, and shoelaces. Surely, this SRM contained lots of strings, and some coders got all tied up in knots.
Division I was won by monsoon with an amazing six challenges. antimatter, ever the speed demon, finished second with three challenges, and in third place was (former blue coder) mlehenbauer, who also had the fastest score on the 500. Ken_Vogel and ZorbaTHut, who had the only submission on the 1000, were the other top finishers.
In Division II, newcomer ryanprichard easily won by more than 100 points, solving all three problems in about 45 minutes and jumping up to an impressive initial rating of 1892. The other top coders in Division II included newcomer jdai and SO?, who has yet to get a Division II question wrong. csd98412 and newcomer xor_freecity rounded out the top 5 in Division II.
The Problems
Chivalry
Used as: Division Two - Level One:
Value 250 Submission Rate 216 / 251 (86.06%) Success Rate 173 / 216 (80.09%) High Score cypressx for 244.84 points (4 mins 8 secs) Average Score 195.04 (for 173 correct submissions)
This problem was a simulation that was inspired by my experience getting off a crowded train. Basically the rules you have to follow are:
- If there's a woman and a man at the front of each line, the woman goes next.
- Otherwise, if there's anyone left on line 1, (it's both women or both men) - take the first person from line 1
- Otherwise, take the first person from line 2.
You also have to consider when one line is empty and the other is not. Taking all of these into account, my solution looked like this:
String out = "";
while (line1.length() > 0 || line2.length() > 0)
{
if (line1.length() > 0 && line1.charAt(0) == 'W')
{
// we don't have to look at line2 because the tie-break rule
// means we'd take line1 anyway
out += 'W';
line1 = line1.substring(1); // consume first person on line 1
}
else if (line2.length() > 0 && line2.charAt(0) == 'W')
{
// we already looked at line1 and it doesn't start with a woman,
// but line2 does, so take it
out += 'W';
line2 = line2.substring(1); // consume first person on line 1
}
else
{
// both start with men
// take first person from line1 if there's anyone left, otherwise line2
if (line1.length() > 0) line1 = line1.substring(1);
else line2 = line2.substring(1);
out += 'M';
}
}
return out;
ShoelaceLength
Used as: Division Two - Level Two:
Value 500 Submission Rate 118 / 251 (47.01%) Success Rate 79 / 118 (66.95%) High Score theflea74 for 442.26 points (10 mins 33 secs) Average Score 300.49 (for 79 correct submissions)
Ok, so I admit, I'm really not that lazy when my shoelaces break. Anyway, to work out this problem, you'd be best off to draw a diagram for yourself; see below.
First, you initialize the length to the starting width (which goes horizontally across the bottom of the laces). Then, for each pair of laces, you add twice the hypotenuse of triangle AED. (You add twice the hypotenuse because there are effectively two laces that cross each other.)
Since the width between the pairs of eyelets increases linearly, you can pre-calculate the difference in the widths from one set to the next as:
double delta = (endWidth - startWidth)/(numPairs - 1.0);
Then, you loop through between the pairs:
// starting length is the starting width (the horizontal distance)
double len = startWidth;
// "current" top width
double width = startWidth;
// pre-calculated difference between widths
double delta = (endWidth - startWidth)/(numPairs - 1.0);
for (int i = 0; i < numPairs - 1; ++i)
{
double nextWidth = width + delta;
double base = (nextWidth + width)/2.0;
len += 2.0*Math.sqrt(base*base + spread*spread);
width = nextWidth;
}
return len;
The height of the triangle (or trapezoid) is a constant, and is given as spread. To clarify the calculation of the hypotenuse of the triangle (the diagonal of the trapezoid), refer to the following diagram.
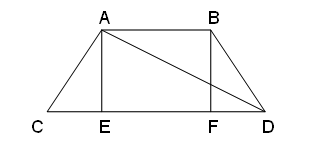
We need to calculate AD, the diagonal of ABDC (or hypotenuse of AED):
AD = sqrt(ED2 + AE2)
From the diagram,
CD = CE + EF + FD
But since ABDC is isosceles,
CD = FD + AB + FD
CD = 2FD + AB
FD = (CD - AB)/2
But what we really need is ED:
ED = EF + FD
Again, since ABDC is isosceles,
ED = AB + FD
From above,
ED = AB + (CD - AB)/2
Therefore,
ED = (AB + CD)/2
And so we can calculate AD as:
AD = sqrt(ED2 + AE2)
AD = sqrt(((AB+CD)/2)2 + AE2)
Uptime
Used as: Division Two - Level Three:
Used as: Division One - Level Two:
Value 1000 Submission Rate 39 / 251 (15.54%) Success Rate 7 / 39 (17.95%) High Score ryanprichard for 656.92 points (23 mins 15 secs) Average Score 531.60 (for 7 correct submissions)
Value 500 Submission Rate 129 / 183 (70.49%) Success Rate 63 / 129 (48.84%) High Score mlehenbauer for 476.35 points (6 mins 23 secs) Average Score 304.99 (for 63 correct submissions)
This problem was based on some real code I wrote for work. As in many TopCoder problems, there are three steps to the solution:
- Parse the input
- Calculate (difference between "now" and "start")
- Format the output
If you reuse your parsing method for both the starting and ending dates, this makes things easier. I wrote a parser that calculates the number of seconds since the start of the given year. First, it calculates the number of seconds in the months between January and the current month (taking leap years into acount), then the number of seconds between the first of the current month and the current time in hours, minutes, seconds.
private static final int days[] = {31, 28, 31, 30, 31, 30,
31, 31, 30, 31, 30, 31};
private static final int leapDays[] = {31, 29, 31, 30, 31, 30,
31, 31, 30, 31, 30, 31};
// returns seconds since midnight of Jan 1 of this year
private int getOffset(String d)
{
// [1-31] [Jan-Dec] [1900-2199] at [1-12]:[00-59]:[00-59] [AM/PM]
String pieces[] = d.split("[ :]");
int year = Integer.parseInt(pieces[2]);
// returns 0 for Jan, 1 for Feb, ... 11 for Dec
int month = getMonthIndex(pieces[1]);
int out = 0;
// seconds between Jan 1 and first of this month
for (int i = 0; i < month; ++i)
{
if (isLeap(year))
out += leapDays[i] * 24*60*60;
else
out += days[i] * 24*60*60;
}
// based on number of days, seconds since beginning of month
out += (Integer.parseInt(pieces[0])-1) * 24*60*60;
// add hours, minutes, seconds
int hh = Integer.parseInt(pieces[4]);
out += hh*60*60;
int mm = Integer.parseInt(pieces[5]);
out += mm*60;
int ss = Integer.parseInt(pieces[6]);
out += ss;
// add 12 hours for PM
if ("PM".equals(pieces[7])) out += 12*60*60;
return out;
}
The difference between start and now is calculated as:
- the number of seconds between the start and ending years,
- minus the number of seconds between Jan 1 of the start year and the start time,
- plus the number of seconds between Jan 1 of the end year and the end time.
After you calculate the number of seconds between the dates, formatting the output is straightforward and has probably been seen (and written) by many of you before:
String out = "";
int days = seconds / (24*60*60);
if (days > 0) out += days + "d "; // note trailing space
seconds -= days * 24*60*60;
int hours = seconds / (60*60);
if (hours > 0) out += hours + "h "; // note trailing space
seconds -= hours * 60*60;
int minutes = seconds / 60;
if (minutes > 0) out += minutes + "m "; // note trailing space
seconds -= minutes * 60;
if (seconds > 0) out += seconds + "s";
return out.trim(); // remove possible trailing space
See ryanprichard's solution for a clean implementation of this exact method.
To save time, some Java coders tried to use java.util.Date, or java.util.Calendar, only to get burned by Daylight Savings Time. If you calculate the time difference yourself, you can't go wrong. Oddly, the C# Date class did work correctly; see mlehenbauer's (short)solution as an example.
TaxicabUsed as: Division One - Level One:
Value 250 Submission Rate 164 / 183 (89.62%) Success Rate 68 / 164 (41.46%) High Score Kawigi for 241.77 points (5 mins 16 secs) Average Score 186.30 (for 68 correct submissions)
This problem turned out to be more difficult than your usual Division I 250. I guess the real algorithm used by the New York City Taxi & Limosine Commission must be worth a lot of money!
The intended solution looks like this. For each minute, calculate the speed. If the speed is more than 6 miles per hour (more than 2 blocks/minute), accumulate one 'unit' for each 1/5 of a mile travelled (this might include fractional units). Otherwise, accumulate one unit for those 60 seconds.
The final calculation is: if there is one unit or less, charge $2.50. Otherwise, charge $2.50 + (number of units - 1)*0.40.
You needed to be careful when converting from blocks to "fifths of a mile" and from blocks/minute to miles per hour.
Kawigi, who also had the high score on this problem, wrote a straightforward implementation of this calculation.
TCMinMinUsed as: Division One - Level Three:
Value 1000 Submission Rate 1 / 183 (0.55%) Success Rate 0 / 1 (0.00%) High Score null for null points (NONE) Average Score No correct submissions
This problem wasn't all that difficult for a Div 1 hard, but it was long. Coders evidently spent a disproportionate amount of time on the 250 and couldn't complete this problem. Sadly, the lone solution (by ZorbaTHut) failed.
You'll need to create a few lookup tables (really "symbol tables" in compiler parlance.) For example:
- Defined functions and their return types
- Local variables for each function
- Parameters for each function
To more easily store multiple pieces of information for each function or variable, I created two data structures:
- Var - to represent a local variable or parameter, its name, and its type, if known.
- Function, which extends Var. This represents a function's name, and return type, and in addition, we store its index (the order that it was originally found in the program). The name and return type are inherited from Var.
Since the number of functions, variables and parameters is limited to 26 (due to the fact that they are all represented by single-lower case characters), these lookup tables can be implemented as arrays:
- One-dimensional array of functions. The index was the function name, minus 'a' (0-25). Each entry is a Function object. If the value at a requested index is null, the function was previously unknown.
- Two-dimensional array of local variables for each function. The first index is the function name (0-25) and the second index is the variable name (0-25); the values are Var objects.
- One-dimensional array of number of parameters to each function. The index is based on the function name.
- Two-dimensional array of parameters to each function. The first index is the function name (0-25) and the second index is the sequence of the parameter in the function definition. Entries in this array are Var objects, which store the name and type.
A global variable, 'changed', is used to indicate that something was changed during this iteration. This is only set to true if a previously unknown (or undiscovered) variable, parameter or function return type was just determined (or discovered.) A 'while' loop will terminate only when this variable didn't change. If nothing was changed, this must mean that the types of all functions, parameters and variables have been determined.
changed = true;
do
{
changed = false;
// calling this might set changed to true
Parse program
} while (changed)
To parse the program, each line is examined one at a time. You can use a finite state machine (FSM) to do this, which takes an action depending on what state we're currently in:
- State 1 - Looking for function definition
- State 2 - Inside a function, parsing variables
- State 3 - Inside a function, processing statements
To simplify the rest of the process, a 'lookup' method can be factored out, as well as a 'unify' method:
Var lookup(name)
Look in current function's local variable table
If not found, look in current function's parameter table for the variable
(exactly one of the above must be true, based on the problem statement)
Var unify(Var a, Var b)
-- "Unifies" the types of a and b
If type of a is known and type of b is not,
set type of b = type of a
set the changed flag
else If type of b is known and type of a is not,
set type of a = type of b
set the changed flag
While in state 1, if the line starts with the string "function", a function declaration is being seen. It is looked up in the Function lookup table. If it doesn't exist yet, its sequence in the program is noted and a Function object is created and added to the function lookup table and the 'changed' flag is set. Whether it was originally found or not, the 'current function' is set to this object. The line is parsed to find the parameter names (and their order) as well as any type information for each one. (At this point, if it's not the first iteration, we cannot learn anything new from this line.) The FSM transitions to state 2 and the next line is inspected.
To determine if we're in state 2, and not 3, the second letter in the current line is inspected. If it is a colon, the line must be a local variable definition. The name and type are added to the current function's information in the lookup table. If this is new information, the changed flag is set. Again, if this is not the first iteration, nothing new will be learned. The FSM remains in state 2 and the next line is examined.
Otherwise, we're in state 3. The line is parsed; afterwards, the FSM remains in state 3. There are four types of statements to consider:
- Simple assignment (a=b) . In this case, the two variables are looked up for the current function, and if either is of unknown type, they can be 'unified'.
- Expresson (a=b+c). In case of * or /, the three variables can all immediately be set to integer types. Otherwise, the three variables' types can be 'unified' if at least one of their types is known.
- Constant assignment (a="b" or a=0). The type of the variable is easily determined and updated in the lookup table.
- Function call (a=f(b)). If a or the return type of f are known, the types can be 'unified'. Furthermore, the types of each of the arguments can be 'unified' with the types of each of the parameters.
While in states 2 or 3, if the line starts with the String "return", the return type of the current function can (possibly) be set. If a variable is being returned, it can be 'unified' with the current Function object. (Since Functions extend Vars, they can be unified with variables.) If it is set for the first time, the 'changed' flag is set (this is taken care of by the unify method.) After the return is seen, we go back to state 1.
After the while loop terminates, we know the types of all the functions, parameters and variables. All that is left is to generate the output.
During parsing, we kept track of the index of each function in the original input as well as the sequence of its parameters. Therefore, we go through each function in order and generate its signature from each of its parameters and its return type. Then, for each defined variable in that function, output their names and types alphabetically, which is easy because the local parameter lookup table -- a two-dimensional array -- is already ordered by function name and variable name.
