December 10, 2017 Single Round Match 722 Editorials
SRM 722 Editorials are now published. Thanks to OB3LISK, square1001, kapillamba4 and asmn for contributing to the editorials. If you wish to discuss the problems or editorials you may do it in the discussion forum here.
SRM 722 Round 1 – Division II, Level One – HillClimber – by OB3LISK
The problem HillClimber gives us a set of mountains, and asks us to find the longest sequence of mountains that increase in height. (Said another way, what’s the longest streak of mountains where we have to continuously climb up, without going down or remaining at the same height.)
We can see that this problem is a simple “Longest Increasing Sequence” (not to be confused with the famous Dynamic Programming problem, “Longest Increasing SUBsequence”).
We’re given an array of mountain heights as input. We’ll need to maintain two variables, the longest sequence of uphill climbing we’ve ever seen, and the sequence of uphill climbing for the mountain series we’re currently on.
Traversing each element of the array of heights from left to right, we’ll keep track of the mountain we’re currently on, and the next mountain in line. If the next mountain is bigger than the mountain we’re currently on, then we know that we’re going uphill, which means we increase our local longest variable by one. It’s also at this step where we decide, “if this local longest is bigger than the longest I’ve seen so far, then we know that this new sequence is the longest I’ve ever seen”, and so we set our total longest the local longest.
After traversing all but the last mountain, our longest uphill sequence variable will contain our final answer.
class HillClimber {
public:
int longest(vector<int>);
};
int HillClimber::longest(vector<int> height)
{
// The longest sequence of increasing mountains.
int longest = 0;
/*
There are n+1 mountains, and n segments.
We care about increasing segments, which means
that mountain i is smaller than mountain i+1.
*/
// Keep track of each increasing sequence of mountains in this variable.
int longestlocal = 0;
// For each of the first n mountains...
for (int i = 0; i < height.size(); i++) {
// The two mountains we're looking at is the current mountain, and the next one.
int mount1 = height[i];
int mount2 = height[i + 1];
// If mount1 is smaller than mount2, then we're going uphill. Increase longestlocal by 1.
if (mount1 < mount2) { longestlocal += 1; // Since we had an increase in height, we should check whether this current sequence is longer than "longest" if (longestlocal > longest) {
// Our longestlocal is the most uphill we've ever seen, so update our longest variable.
longest = longestlocal;
}
} else { // If the mount1 is bigger than mount2 (or equal), then we aren't going uphill!
// Reset longestlocal to 0.
longestlocal = 0;
}
}
return longest;
}
The complexity of our solution is O(N), as we have to visit each segment of a mountain only once. The space complexity for our solution is O(1), as we only need two variables of space (“longest” and “longestlocal“) to hold the longest uphill sequence.
SRM 722 Round 1 – Division II, Level Two – TCPhoneHomeEasy – by square1001
What is this problem?
You are required to count the number of (digits)-digit integers (let’s call them “good integers”, leading zeros are allowed), for which there are no prefix that is equal to one of the elements of specialPrefixes.
For example, if digits=3 and specialPrefixes={“1”, “23”, “456”}, the answer is 889. Since there are only 111 integers (“100” to “199”, “230” to “239”, and “456”) for which one of the prefixes is in specialPrefixes, the answer is 1000 – 111 = 889.
The Solution
Consider the example where digits=4. What are the integers with the prefix “25”? The answer is all integers between 2500 and 2599.
More generally, if digits=d, the integers which the prefix s, all integer between l = 10^d-|s| * int(s) and r = 10^d-|s| * (int(s) + 1) – 1 (|s| denotes the length of s, and int(s) denotes the transformation of s from string format to integer).
So, for each element s in specialPrefixes, you can find l, r for them. The number x is good integer if and only if there are no s which is l ≤ x ≤ r. Now you can brute-force the value x (the range is 0 ≤ x < 10^digits).
Time Complexity: O(10^digits * K). K equals to number of special prefix.
Memory Complexity: O(digits * K)
C++ Code:
#include <string>
#include <vector>
using namespace std;
int l[55], r[55];
class TCPhoneHomeEasy {
private:
int power(int a, int b) {
int ret = 1;
for(int i = 0; i < b; i++) {
ret *= a;
}
return ret;
}
public:
int validNumbers(int digits, vector<string> specialPrefixes) {
int n = specialPrefixes.size();
for(int i = 0; i < n; i++) {
string s = specialPrefixes[i];
l[i] = power(10, digits - s.size()) * stoi(s);
r[i] = power(10, digits - s.size()) * (stoi(s) + 1) - 1;
}
int all = power(10, digits);
int answer = 0;
for(int i = 0; i < all; i++) {
bool good = true;
for(int j = 0; j < n; j++) {
if(l[j] <= i && i <= r[j]) good = false;
}
if(good) answer++;
}
return answer;
}
};
SRM 722 Round 1 – Division II, Level Three – MulticoreProcessingEasy by kapillamba4
You are given 2 arrays of the same size, one represents the speed of computation of a system and other – the maximum number of cores of a system.
A work requires jobLength units of computation and if number of cores utilized is ‘x’ then work gets divided between them as jobLength/x per core
corePenalty is penalty imposed on computation time for each core utilized beyond one.
Therefore final formula comes out to be:
computationTime = ((jobLength / cores) / speed) + corePenalty*(cores-1)
We have to choose a system and number of cores to utilize such that total computation time is minimum. We will iterate over each system and its number of cores calculating minimum computation time for each iteration.
We must return a minimum integer value for computationTime therefore we round up the value of computationTime and return it.
C++Code:
#include <bits/stdc++.h>
class MulticoreProcessingEasy {
public:
int fastestTime(int jobLength, int corePenalty, std::vector <int> speed, std::vector <int> cores) {
double ans = 99999999999.0;
for(int i = 0; i < speed.size(); i++) {
for(int c = 1; c <= cores[i]; c++) {
ans = std::min(ans, ((double)(jobLength)/c)/speed[i]+corePenalty*(c-1));
}
}
return std::ceil(ans);
}
}
SRM 722 Round 1 – Division I, Level One – TCPhoneHome by square1001
What is this problem?
You are required to count the number of (digits)-digit integers (let’s call them “good integers”, leading zeros are allowed), for which there are no prefix that is equal to one of the elements of specialPrefixes.
For example, if digits=3 and specialPrefixes={“1”, “23”, “456”}, the answer is 889. Since there are only 111 integers (“100” to “199”, “230” to “239”, and “456”) for which one of the prefixes is in specialPrefixes, the answer is 1000 – 111 = 889.
The integer digits is at most 17.
The Solution
The digits can be up to 17, so of course you cannot brute-force x. You have to come up with more efficient solution.
The idea is that, for example, if there’s element “123” and “12345” in specialPrefixes, “12345” has no additional impact on the answer. Generally, suppose if there are element s and t, and s is a prefix of t, t has no meaning. So, you can erase t from specialPrefixes. When there is no meaningless element in specialPrefixes, the answer is 10^digits – (sum of 10^digits-|s| for each element s in specialPrefixes), letting |s| = (length of s).
Why this way can get the correct answer? Suppose that there is no meaningless element in specialPrefixes. You have to prove that there is no integer x that there are two or more of it’s prefixes in specialPrefixes. If there are two prefixes of x, saying s and t in specialPrefixes, you can say that “s is a prefix of t” or “t is a prefix of s”. It means s or t is a meaningless element, so it makes contradiction.
You can erase all meaningless element in specialPrefixes in this way:
1) check there are pair of distinct numbers (x, y) such that specialPrefixes[x] is a prefix of specialPrefixes[y]. If there are no such pair, this is the end of routine.
2) if there are such pair (x, y), erase specialPrefixes[y] and go back to operation (1).
Time Complexity: O(K^3). K equals to number of special prefixes.
Memory Complexity: O(K)
Alternative Solution
The idea is that you can determine integers l and r that the number has prefix s if and only if the number is between l and r. For example, 10-digit integer which has prefix “869120” is, between 8691200000 and 8691209999.
If you process naively it seems like taking O(10^digits * K) if K is equals to the number of special prefix, and obviously it gets Execution Time Limit Exceeded. But you can use “coordinate compression” technique for this problem and calculate faster.
You can reduce to the following problem: You are given array l, r with length K. How many (digits)-digit number integer x that there are no integer k that l[k] ≤ x < r[k]. There are at most 2K distinct elements in l and r, so use coordinate compression and you only have to check x for less or equal to these 2K elements. Finally this works in time complexity O(K^2).
C++ Code
#include <bits/stdc++.h>
using namespace std;
class TCPhoneHome {
public:
long long power(int a, int b) {
long long ret = 1;
for(int i = 0; i < b; i++) ret *= a;
return ret;
}
long long validNumbers(int digits, vector<string> specialPrefixes) {
while(true) {
bool found = false;
for(int i = 0; i < specialPrefixes.size() && !found; i++) {
for(int j = 0; j < specialPrefixes.size() && !found; j++) {
if(i == j) continue;
string s = specialPrefixes[i];
string t = specialPrefixes[j];
if(s == t.substr(0, s.size())) {
// string t has no meaning
specialPrefixes.erase(specialPrefixes.begin() + j);
found = true;
}
}
}
if(!found) break;
}
long long ret = power(10, digits);
for(string s : specialPrefixes) ret -= power(10, digits - s.size());
return ret;
}
};
SRM 722 Round 1 – Division I, Level Two – MulticoreProcessing by kapillamba4
You are given 2 arrays of same size n, one represents the speed of computation of a system and other the maximum number of cores of a system.
A work requires jobLength units of computation and if number of cores utilized are ‘x’ than work gets divided between them as jobLength/x per core.
corePenalty is penalty imposed on computation time for each core utilized beyond one.
For each system we know its computation speed, therefore we can calculate minimum computation time for each system by varying the its number of utilized cores: 1 <= cores <= maximum_cores
Therefore final formula comes out to be:
computationTime = ((jobLength / cores) / speed) + corePenalty*(cores-1);
We can observe that the above formula represents a familiar graph of
f(x) = c1/x + c2*x, more information here
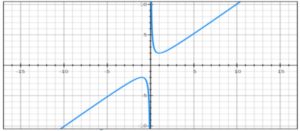
If we iterate linearly over all systems and overall possible utilized cores values, time complexity will be Θ(Σ(speed[i]*cores[i])) where 0 <= i < n.
However we can reduce the time complexity to Θ(Σ(speed[i]*log(cores[i]))) by using ternary search for finding minima for above formula for each system separately.
Here is a good article which explains how ternary search works and here is another good article from TopCoder Cookbook.
We must return a minimum integer value for computationTime therefore we round up the value of computationTime before returning it.
C++ Code
#include <bits/stdc++.h>
class MulticoreProcessing {
const double eps = 0.00001;
public:
double floatMin(long long jobLength, int corePenalty, int speed, double c) {
return ((((double)jobLength)/c)/speed+corePenalty*(c-1));
}
long long longMin(long long jobLength, int corePenalty, int speed, long long c) {
return (((jobLength+c-1)/c+speed-1)/speed+corePenalty*(c-1));
}
long long ternary(long long jobLength, int corePenalty, int speed, int n) {
double r = n, l = 1;
while(fabs(r - l) > eps) {
double m1 = l+(r-l)/3;
double m2 = r-(r-l)/3;
double f1 = floatMin(jobLength, corePenalty, speed, m1);
double f2 = floatMin(jobLength, corePenalty, speed, m2);
if(f1 > f2) {
l = m1;
} else {
r = m2;
}
}
return std::min(longMin(jobLength, corePenalty, speed, floor(l)),
longMin(jobLength, corePenalty, speed, ceil(l)));
}
long long fastestTime(long long jobLength, int corePenalty,
std::vector <int> speed, std::vector <int> cores) {
long long ans = std::numeric_limits<long long>::max();
for(int i = 0; i < speed.size(); i++) {
ans = std::min(ans, ternary(jobLength, corePenalty, speed[i], cores[i]));
}
return ans;
}
};
SRM 722 Round 1 – Division I, Level Three – DominoTiling by asmn
You are given a 2D rectangular grid with some cells need to be covered by disjoint 2×1 dominos. Your goal is to calculate the number of ways to do that.
The idea is to use dynamic programing to do a row by row calculation. For each row r, we only consider placing horizontal dominos covering cells in row r and vertical dominos covering cells in row r and r+1. Use binary number mask to represent the placement of vertical dominos in row r. Placement of vertical dominos in row r-1 and cells don’t need to be covered is represented as binary number pMask and rowMask. In the following figure, mask is (0000101)2, rowMaskis (0100000)2 and pMask is (1000010)2. The tuple (mask, pMask, rowMask) is considered valid if there is a valid dominos placement covering all cells in the row. That means (mask, pmask, rowMask) are all disjoint and the cells uncovered can be covered by horizontal dominos.
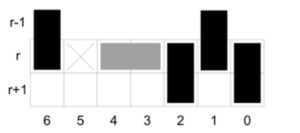
When we finish placing dominos in row 0 ~ r-1, let count[r][mask] to be the number of valid ways to fully cover row r with placement mask. The transfer function can be represented as:
In a n*m grid, the start condition is count[-1][(00..0)2] = 1, and the final answer is count[n-1][ (00..0)2].
To speed up calculation, we can perform 2 optimizations:
1. Instead of checking each (pMask, rowMask[r], mask), we pre calculate all valid mask for each pMask(assuming rowMask[r]=0) by dfs(depth first seach) on all valid placement in a row.
2. Since we only need row r-1’s information, all previous information can be discarded.
Python Code
def calcT(mask, n):
ret = []
A = ''.join(('1' if mask & 1 << i > 0 else '0') for i in range(n))
def dfs(k, now):
if k >= n:
ret.append(int(now, 2))
else:
dfs(k + 1, (('0' if A[k] == '1' else '1')) + now)
if A[k:k + 2] == '00':
dfs(k + 2, '00' + now)
dfs(0, '')
return ret
class DominoTiling:
def count(self, grid):
n = len(grid[0])
nMask = 1 << n
T = [calcT(mask, n) for mask in range(nMask)]
countNow = [1] + [0] * (nMask - 1)
for row in grid:
countNext = [0] * nMask
rowMask = int(row.replace('.', '0').replace('X', '1'), 2)
for pMask in range(nMask):
if pMask & rowMask > 0:
continue
for mask in T[pMask | rowMask]:
countNext[mask] += countNow[pMask]
countNow = countNext
return countNow[0]
It is easily to see that the overall time complexity is O(n*4^m), where n is number of rows and m is the number of columns. The memory space complexity is O(4^m).
Harshit Mehta
Sr. Community Evangelist


