June 7, 2022 Single Round Match 828 Editorials
SlidingDoors
The problem can be solved by pure simulation of sliding the panels one at a time, but there are other solutions that are much simpler to implement. The main idea is to realize that we don’t actually have to return a sequence of instructions how to push the panels, just a “picture” of the final state. Here are two such solutions:
- For each rail, if rail[S] has a panel, change that character to ‘.’ and change any other ‘.’ on that rail to ‘-’.
- For each rail, count the number P of panels and then produce a completely new string in which the P leftmost characters are ‘-’ (but skipping character S if it were among them) and the rest are ‘.’
The validity of both of these solutions depends on the observation that for each rail each possible configuration of panels can actually be produced by sliding the panels in the allowed way. (For a formal proof, imagine that you first push all panels all the way to the right, and then you imagine your desired configuration of panels, push the first panel left until it’s in the correct place, then push the second panel to its correct space, and so on.)
The code below shows the second of the two solutions described above
public String[] openSection(int N, String[] rails, int S) {
int[] dashes = new int[2];
for (int r=0; r<2; ++r) {
for (char c : rails[r].toCharArray()) if (c == '-') ++dashes[r];
}
String[] answer = new String[2];
for (int r=0; r<2; ++r) {
answer[r] = "";
for (int n=0; n<N; ++n) {
if (n == S) {
answer[r] += '.';
continue;
}
if (dashes[r] > 0) {
answer[r] += '-';
--dashes[r];
} else {
answer[r] += '.';
}
}
}
return answer;
}
ShortShortSuperstring
In the optimal solution each character of the superstring must be a part of at least one of the three given strings. This is easy to show: leaving out unused characters from a superstring keeps it a superstring and it makes it shorter.
As the short strings have length <= 5 and there are no unused letters, the shortest superstring has length at most 15.
There are various ways to proceed from this point. The general rule of thumb in problems like this is that we want a solution that has as few special cases as possible. And usually a good way of obtaining such a solution is by using as much brute force as possible.
In our solution we will iterate over all L from max(lengths of A, B, C) to sum(lengths of A, B, C) until we find one for which some superstrings exist.
For a fixed L we will iterate over all O(L^3) triples of indices: we will use brute force to try out all possibilities where in L we can find one specific occurrence of A, B, and C. For each of these combinations, we then do the following:
- Start with a string of L ‘?’ characters.
- Write the letters of A starting from its current offset.
- Then do the same with B, and then with C (each time possibly overwriting some previous characters).
- Verify whether the string we obtained still contains A and B as substrings. (For good measure we can also verify C, but as that was the last string we wrote, we know it’s still there.)
- If it does, we must have found a solution. (And as we know that this must be the shortest solution, we don’t even have to check whether some ‘?’ remained – we know that this cannot happen.)
This solution has no special cases and it clearly examines all possible solutions so we can be sure not to miss any. The only thing we should still note is that it may generate the same solution more than once (e.g., if A=”aaaaa” and B=C=”a”), so we need to discard all duplicates before returning the solutions we found. In our implementation we use a TreeSet to store the answers – this sorts them for us and discards all duplicates at the same time.
String join(char[] data) {
String answer = "";
for (char x : data) answer += x;
return answer;
}
public String[] constructAll(String A, String B, String C) {
int LA = A.length(), LB = B.length(), LC = C.length();
int minL = Math.max( LA, Math.max( LB, LC ) );
TreeSet<String> answers = new TreeSet<String>();
for (int L=minL; L<=15; ++L) {
for (int a0=0; a0<=L-LA; ++a0)
for (int b0=0; b0<=L-LB; ++b0)
for (int c0=0; c0<=L-LC; ++c0) {
char[] letters = new char[L];
for (int i=0; i<L; ++i) letters[i] = '.';
for (int i=0; i<LA; ++i) letters[i+a0] = A.charAt(i);
for (int i=0; i<LB; ++i) letters[i+b0] = B.charAt(i);
for (int i=0; i<LC; ++i) letters[i+c0] = C.charAt(i);
String candidate = join(letters);
if (candidate.indexOf(A) == -1) continue;
if (candidate.indexOf(B) == -1) continue;
if (candidate.indexOf(C) == -1) continue;
answers.add(candidate);
}
if (!answers.isEmpty()) {
int N = answers.size();
String[] output = new String[N];
int i = 0;
for (String candidate : answers) output[i++] = candidate;
return output;
}
}
return new String[0];
}
ImproveName
A set of letters cannot be used to improve the letter if and only if they already appear in sorted order. In all other cases sorting the set of letters improves the name. The total number of ways to select exactly K out of N letters is the binomial coefficient (N choose K). Thus, we can count the good sets by counting the bad sets and then subtracting their count from the total.
If we look at the company name as a sequence of characters, the task “count all bad sets of letters” is simply the task “count all non-decreasing subsequences of length exactly K”. This is a very standard task we can easily solve.
The reference solution shown below runs in O(KN log N) time and uses Fenwick trees to speed up a slower O(KN^2) solution.
The O(KN^2) solution is a simple application of dynamic programming: for each index i and each length j we want to calculate the value dp[i][j] = the number of non-decreasing subsequences of length j that end with the character at index i. Each of these values can be calculated from some previous ones: dp[i][j] is the sum of dp[k][j-1] over all k<j such that the character at index j can follow the character at index k.
The improved running time comes from choosing a smarter data structure to do the sum and choosing a different order in which we compute the values.
Imagine that we start with an empty string, then all ‘A’ characters appear (one by one, left to right), then all ‘B’s, and so on. Whenever a character appears at some index i, we will compute all the values dp[i][*]. The indices k to consider are precisely the indices of letters that have already appeared to the left of i. Thus, dp[i][j] is a sum of all the already-computed values dp[*][j-1] to the left of position i. And this sum can be computed in logarithmic time by using a suitable data structure (e.g., a Fenwick tree or an interval tree) to store the already computed values. (More precisely, in our solution we use one separate tree for each value j.)
private static class Fenwick {
long[] T;
Fenwick() { T = new long[5047]; }
void update(int x, long delta) {
while (x < T.length) { T[x] += delta; x += x & -x; }
}
long sum(int x1, int x2) {
long res=0;
--x1;
while (x2 > 0) { res += T[x2]; x2 -= x2 & -x2; }
while (x1 > 0) { res -= T[x1]; x1 -= x1 & -x1; }
return res;
}
};
public int improve(String currentName, int K) {
int N = currentName.length();
long MOD = 1_000_000_007;
long[][] binomial = new long[N+1][];
for (int n=0; n<=N; ++n) {
binomial[n] = new long[n+1];
for (int k=0; k<=n; ++k) {
if (k == 0 || k == n) {
binomial[n][k] = 1;
} else {
binomial[n][k] = (binomial[n-1][k-1] + binomial[n-1][k]) % MOD;
}
}
}
Fenwick[] FT = new Fenwick[K+1];
for (int k=0; k<=K; ++k) FT[k] = new Fenwick();
long[] dp = new long[K+1];
long total = 0;
for (char ch='A'; ch<='Z'; ++ch)
for (int n=0; n<N; ++n) if (currentName.charAt(n)==ch) {
dp[1] = 1;
for (int k=2; k<=K; ++k) dp[k] = FT[k-1].sum(1,n) % MOD;
for (int k=1; k<=K; ++k) FT[k].update(n+1,dp[k]);
total += dp[K];
}
long answer = binomial[N][K] - total;
answer %= MOD; answer += MOD; answer %= MOD;
return (int) answer;
}
ContiguousConstantSegment
Let’s start with some basic casework. We can do a histogram to find the value with the most occurrences in the given array. Let M be that number of occurrences. If we have to do N-M edits or more, we can almost always make all elements equal, with just one exception: if N > 1, all elements are already equal (M=N) and we have to do exactly one edit, we are forced to change one element and the best we can end with is just N-1 equal elements in a row, followed or preceded by the changed one.
(Note that the “N > 1” part in the previous paragraph is easy to miss. If we have one element and we are forced to do one edit, we must change its value to a new one, but in this special case that new value is now the one with the most occurrences and we still do have a constant segment of length 1, we don’t go down to 0.)
Proof of the above statement:
- If we have exactly E = N-M edits, we can make all elements equal.
- If we have at least two extra edits, we can also make all elements equal – e.g., by spending N-M edits to make them equal, then all but one of the remaining edits changing one element to a new incorrect value, and the final edit to fix that element back to its correct value.
- If we have exactly one extra edit and M < N, we do the same as in the case without the extra edit, just instead of setting the last element directly to the correct value we first set it to an incorrect one.
- This leaves us with the case of a constant array and a single edit, and we already analyzed that one.
What remains are the cases when E < N-M, i.e., we don’t have enough edits to make the entire array constant.
Below we’ll show the asymptotically optimal solution: a linear pass over the array with two pointers. (Solutions with an extra logarithm in time complexity were plenty fast to get accepted too.)
The key observation we need is the property “can this segment be turned into a constant segment?” is monotonous: if a segment has it, all its sub-segments have it too (because making the same set of edits makes them constant).
In order to determine whether a segment has the desired property, we need to know the maximum number of occurrences of any element within that segment. (The best way of turning this segment into a constant segment is to edit all elements except for a fixed one that has the most occurrences.)
We will examine some segments. While we do so, we will maintain a histogram of the segment we are currently examining – i.e., for each element we will have its number of occurrences within the current segment, and for each count we will maintain the number of elements that have it. Additionally, we will separately maintain the maximum of those counts. This allows us to tell in constant time whether the current segment can become constant or not (we just look at its length and maximum count). And we can update this information in constant time whenever we append a new element to the segment, or remove the first element of the segment.
We will iterate over all options for where the optimal segment begins. For each beginning we then increment the end until we find the point where the segment no longer can be constant (or hit the end of the array).
public int produce(int N, int MOD, int[] Aprefix, int seed, int E) {
int[] A = new int[N];
for (int n=0; n<Aprefix.length; ++n) A[n] = Aprefix[n];
long state = seed;
for (int n=Aprefix.length; n<N; ++n) {
state = (state * 1103515245 + 12345) % (1L << 31);
long curr = (state / 16) % MOD;
A[n] = (int)curr;
}
int[] fullHistogram = new int[MOD];
for (int a : A) ++fullHistogram[a];
int maxCnt = 0;
for (int cnt : fullHistogram) maxCnt = Math.max( maxCnt, cnt );
int minEdits = N - maxCnt;
if (E == minEdits) return N;
if (E == minEdits + 1) {
if (N == 1) return 1;
if (minEdits == 0) return N-1;
return N;
}
if (E >= minEdits + 2) return N;
// for each value its current count in the window
int[] histogram = new int[MOD];
// for each value in histogram[] its number of occurrences
int[] aggregate = new int[N+1];
aggregate[0] = MOD;
int best=0, lo=0, hi=0, maxfreq=0;
while (true) {
if (hi-lo-maxfreq <= E) {
// check for the new best solution
best = Math.max(best,hi-lo);
// increment end to extend the segment
if (hi==N) break;
--aggregate[ histogram[ A[hi] ] ];
++histogram[ A[hi] ];
++aggregate[ histogram[ A[hi] ] ];
if (histogram[ A[hi] ] > maxfreq) maxfreq = histogram[ A[hi] ];
++hi;
} else {
// increment beginning to shrink the segment
--aggregate[ histogram[ A[lo] ] ];
--histogram[ A[lo] ];
++aggregate[ histogram[ A[lo] ] ];
while (aggregate[maxfreq]==0) --maxfreq;
++lo;
}
}
return best;
}
HexagonTiled
The solution consists of two related steps: realizing that the number of vertical diamonds remains constant over all valid tilings (and in fact, is always equal to B*C in our notation), and counting the tilings of the given hexagon. The final answer is then the product of those two counts.
A nice way to see why all tilings share the same number of diamonds of each rotation is to notice the bijection between these tilings and some patterns of cubes in 3D. Consider the following image:
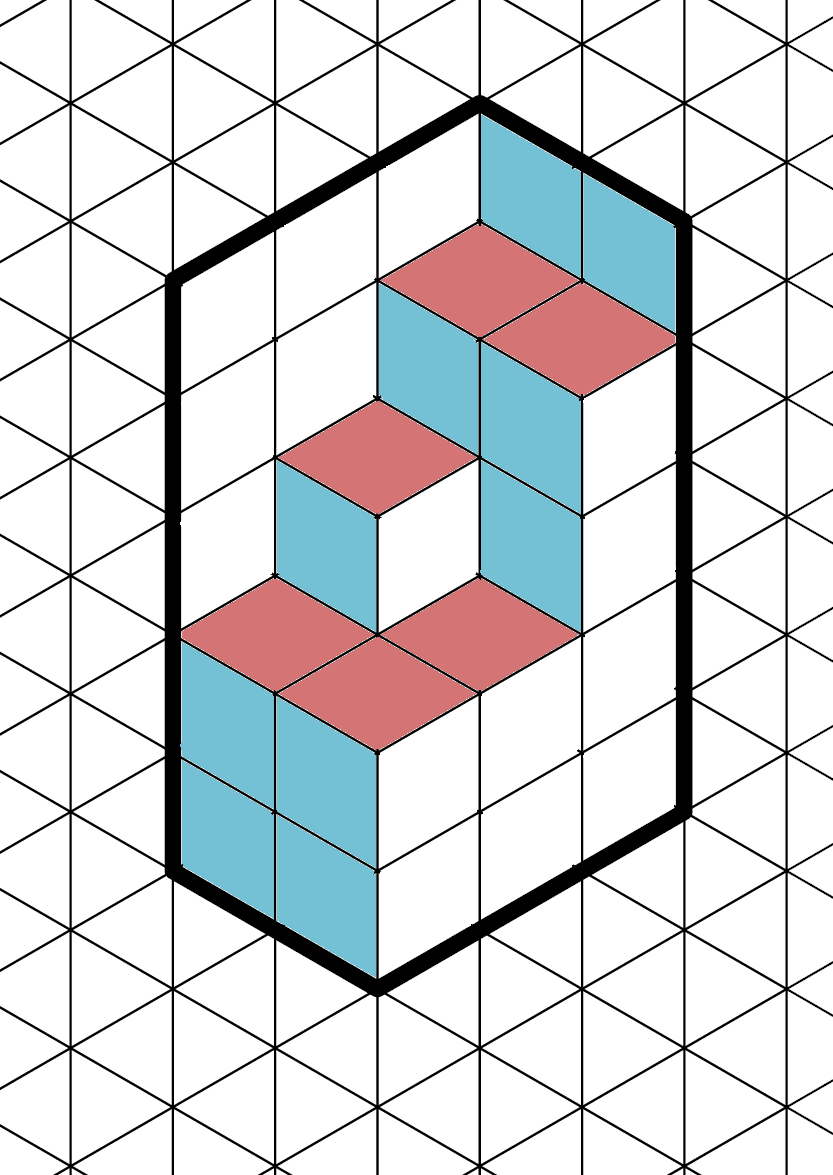
This is one of the valid tilings of a (2,3,5)-hexagon. But we can see the same image as a “corner” (the inside of a 2x3x5 box) that is partially filled with unit cubes. For each unit cube, the “top” face is red, the “left” face is blue and the “front” face is white.
We can now see that all valid tilings correspond to all ways of partially filling the corner with unit cubes in a “convex” way: for each cube that is present all cubes between it and the corner (in the Manhattan metric) must also be present. These arrangements are called plane partitions – see https://en.wikipedia.org/wiki/Plane_partition.
Adding a cube does not change the number of white, blue and red faces we see, so for any valid tiling their counts must be the same – and in particular, they must be the same as the numbers for the tiling that corresponds to the empty corner. Thus, for an (A,B,C)-hexagon we have A*B red, A*C blue, and B*C white diamonds in each valid tiling.
The total number of tilings of an (A,B,C)-hexagon has a rather nice compact formula:
H(A+B+C) * H(A) * H(B) * H(C) / ( H(A+B) * H(A+C) * H(B+C) )
where H(0) = H(1) = 1 and H(n) = 1! * 2! * … * (n-1)! for n > 1.
Note that our tilings are essentially perfect matchings in a planar bipartite graph. The paper https://arxiv.org/pdf/math/9410224.pdf (Kuperberg: Symmetries of plane partitions and the permanent-determinant method) contains a nice exposition of one way of counting these matchings and of more general techniques that can be used to solve problems of this type.
misof


