October 20, 2020 Single Round Match 791 Editorials
Div2Easy: TableTennisGame
The first observation is that each serve will correspond to a point, so A + B will be the total points of 2 players. The second observation is that, since 2 players serve alternately after every 2 (or 1) exchanges, the values of A and B can not be too far away.
There are 3 cases to be considered.
Case 1: A + B < 11
In this case, clearly no one has earned 11 points yet, you should return [] in this case.
Case 2: 11 <= A + B <= 20
In this case, “deuce” cannot occured, 2 players serve alternately every 2 exchanges. There are 2 conditions for A, B to be valid:
- |A – B| <= 2
- At least A or B must be even.
Many participants failed because of the lack of checking condition 2) above. If both conditions are satisfied, then A and B will correspond to a valid table tennis game where the winner got 11 points, the loser got A + B – 11 point(s).
Case 3: A + B > 20
In this case, “deuce” must occured. When the score reaches 10-10, 2 players serve alternately and a player will win immediately when he/she is 2 points ahead of his/her opponent. Therefore the number of serves after “deuce” must be an even number, thus A and B must be equal. We have W + L = A + B and W – 2 = L, solve this and we get W = A + 1, L = A – 1.
Implementation:
import java.io.*;
import java.lang.*;
public class TableTennisGame {
public int[] finalScore(int a, int b) {
if (a + b < 11) return new int[0];
if (a + b <= 20) { // a + b >= 11
if (Math.abs(a - b) <= 2 && (a % 2 == 0 || b % 2 == 0) ) return new int[] {11, a + b - 11};
else return new int[0];
}
else { // a + b > 20
if (a != b) return new int[0];
return new int[] {a + 1, a - 1};
}
}
}
Div2Medium: NearPalindromesDiv2
What condition must be satisfied for a string to be an even near-palindrome?
It is straightforward to see that each letter in an even palindrome will occured an even number of times. The reverse is also true. If all letters appeared an even number of times in an even length string then this string is a near-palindrome string.
Let k be the number of letters which has odd occurrences in string S. Note that k will be even since the length of S is also even. We need to perform a minimum number of operations to make k = 0.
How k changes when an operation is made?
Assume we change letter x to letter y in an operation. The parity of occurrences of letter x will change, from odd to even and from even to odd. The same holds for letter y. Therefore k will:
- not change if x and y have different parity in occurences before the operation.
- +2 if both x and y appeared an even number of times before the operation.
- -2 if both x and y appeared an odd number of times before the operation.
So, the minimum number of operations needed is k/2 which we can obtain by repeatedly choosing 2 odd occurrence letters and changing one to another until all letters have even occurrences. The last question is which odd occurence letter should turn into which odd occurence letter to make S lexicographically smallest.
Making S lexicographically smallest
By definition, in order to make S lexicographically smallest, we should make the first character of S smallest. Among ways to make the first character of S smallest, we choose ones where the second character of S is smallest. And so on.
So, we will scan characters of S from left to right. For each character, we will try to make it as small as possible. Assume we are considering letter x. There are 2 cases:
- x is an even occurrence letter
Clearly we cannot change x, so we left it untouched.
- x is (currently) an odd occurrence letter.
If x is smallest among all (currently) odd occurrences letters, we should not change it to others as this will make S lexicographically larger. Otherwise, it is optimal to change x to the (current) smallest odd occurrence letter.
Implementation:
import java.io.*;
import java.util.*;
public class NearPalindromesDiv2 {
int indexOf(int[] a, int v) {
for(int i = 0; i < a.length; ++i)
if (a[i] == v)
return i;
return -1;
}
public String solve(String s) {
int[] odd = new int[26];
for(int i = 0; i < 26; ++i) {
int occ = 0;
for(int j = 0; j < s.length(); ++j)
if (s.charAt(j) - 'a' == i) occ += 1;
odd[i] = occ % 2; // odd[i] = 1 means i is odd-occurrence letter
}
StringBuilder res = new StringBuilder();
for(int i = 0; i < s.length(); ++i) {
char c = s.charAt(i);
if (odd[c - 'a'] == 0) res.append(c); // if c is an even-occurrence letter, we can't change it
else {
int j = indexOf(odd, 1); // find j where j is the current smallest odd-occurrence letter
if (j == c - 'a') res.append(c); // if c is smallest odd-occurrence letter, we should not change it
else {
res.append((char)( (int)('a') + j )); // it is optimal to change c to j
odd[j] = 0; odd[c - 'a'] = 0; // now c and j are even-occurrence letter
}
}
}
return res.toString();
}
}
Div2Hard: RandomDijkstraDiv2
Let C be the number of ordering of N nodes such that when N nodes are removed from S in this order, the distance array D[] will be correctly computed. The probability we need to find will be C / N! where N! = 1 * 2 * .. * N is the number of all possible ordering of N nodes.
Dynamic programming approach
Since the constraint is small (N <= 15), an experienced participant can see that counting C can be approached by dynamic programming method in which we will simulate the Dijkstra algorithm by keep track for each node 2 information: is it removed from S or not yet, is its D[] corrected or not yet. However, this may cause 4^N states in total which is too much. We need to have some useful observations in order to reduce the number of states.
Once a node is removed from S, its D[] won’t change after that.
As presented in the pseudo-code, only D[] of nodes in S can be changed. So once a node is removed from S, its D[] should already be corrected at that moment. Knowing this, for a given node we only care 3 things (instead of 4):
- It is removed from S
- It isn’t removed from S yet and its D[] is already corrected
- It isn’t removed from S yet and its D[] is not corrected yet.
So we now reduce the number of states down to 3^N which is small enough for N <= 15.
The transition of DP
The state of N nodes can be represented by a number of N digits written in base 3 (whose value in base 10 will be in range [0, 3^N – 1] ) where each digit will describe the current state of each node.
Let dp(X) be the number of ways of removing nodes from S such that we can reach state X where X is a number in base 3 that describes the current state of N nodes. C will be equal to dp() of state in which all nodes were removed.
Following is a way of computing the dp() table using a bottom-up approach. Suppose dp(X) is already computed.
- From X, we know the set Y of nodes which were not removed from S yet and their D[] are already corrected. The next node removed from S should be one node in Y.
- For each node u in Y, consider removing it from S next. If D[] of some node v is not corrected yet, they now can be corrected when u is removed. If correct_D[v] = correct_D[u] + dist(u, v), then D[v] is now corrected where correct_D[v] is the correct shortest distance from 0 to v.
- When u is removed, the new state of N nodes, denoted by X’, can be determined. By the counting principle rules of sum, dp(X’) will increase by dp(X).
So the entire dp() table can be computed in O(3^N * N^2) since each transition takes O(N^2) (you can reduce it to O(N) but it’s not necessary). You can see the full implementation below for details.
An even faster algorithm
There exists a dynamic programming algorithm with only 2^N states. You could find it out after reading the below solution for the problem RandomDijkstraDiv1 (remember to read its problem statement, too. It has a minor difference compared to this problem).
Implementation:
import java.io.*;
import java.util.*;
public class RandomDijkstraDiv2 {
static int INF = (int)(1e9);
int n;
int cost[][];
int pow3[], dist[];
// do Bellman Ford to find shortest distance from 0 to others
void bellman_ford() {
dist = new int[n]; Arrays.fill(dist, INF); dist[0] = 0;
for(int k = 0; k < n; ++k) {
for(int i = 0; i < n; ++i)
for(int j = 0; j < n; ++j)
if (dist[j] > dist[i] + cost[i][j])
dist[j] = dist[i] + cost[i][j];
}
}
// check whether there exists a shortest path of the form 0->...->u->v
boolean sp_prev(int u, int v) { return dist[v] == dist[u] + cost[u][v]; }
// get the digit at n-th position in base 3 representation of x
int base3_digit(int x, int n) { return (x / pow3[n]) % 3; }
public double solve(int _n, int[] g) {
n = _n;
// transform g to 2D array cost for convenience
cost = new int[n][];
for(int i = 0; i < n; ++i) {
cost[i] = new int[n];
for(int j = 0; j < n; ++j) cost[i][j] = g[i * n + j];
}
bellman_ford();
pow3 = new int[n + 1];
pow3[0] = 1; for(int i = 1; i <= n; ++i) pow3[i] = pow3[i - 1] * 3;
long dp[] = new long[ pow3[n] ];
// 0 : not removed yet + its D[] is not corrected yet
// 1 : not removed yet + its D[] already corrected
// 2 : is removed + its D[] MUST correct at the moment it was removed
dp[1] = 1; // initially, all nodes were not removed yet and only D[0] is corrected
// do a bottop-up dp
long tot = 0;
for(int cur = 0; cur < pow3[n] - 1; ++cur) {
if (dp[cur] == 0) continue;
for(int u = 0; u < n; ++u)
if (base3_digit(cur, u) == 1) {
// u is not removed yet + D[u] is already corrected
// now consider remove u
int nxt = cur + pow3[u]; // change state of u from 1 to 2
for(int v = 0; v < n; ++v)
if (base3_digit(cur, v) == 0 && sp_prev(u, v) == true)
nxt += pow3[v]; // if removing u helps correct D[v], change state of v from 0 to 1
dp[nxt] += dp[cur];
}
}
long fact = 1; for(int i = 1; i <= n; ++i) fact *= i;
double res = (double)(dp[ pow3[n] - 1]) / fact;
return res;
}
}
Div1Easy: NearPalindromesDiv1
What condition must be satisfied for a string to be a near-palindrome?
In a palindrome, if we don’t count the center (if any), each letter will appear an even number of times. There will be at most one letter appear an odd number of times in a palindrome. The reverse is also true. If a string has at most one odd occurrence letter, we can rearrange its characters to turn it into a palindrome, thus it is a near-palindrome string.
Let O be the set of letters which has odd occurrences in string S. We need to perform a minimum number of operations to make |O| <= 1.
How O changes when an operation is made?
It is useful to imagine all lowercase letters in a ring. Let’s divide a ring into 26 sections, each section will correspond to a letter. For an odd occurrence letter, we will put a black piece to the section corresponding to it. These black pieces will represent the set O. Below is an illustration in which O = {‘a’, ‘m’, ‘z’, …}

Assume in an operation we change letter a to letter b (b = a + 1 or b = a – 1).
If both a and b appeared an even number of times before the operation, after the operation they both have odd occurrences, the size of O increases by 2. The operation is thus corresponding to putting 2 black pieces at 2 empty adjacent sections a and b on the ring.

If a has odd occurrences and b has even occurrences before the operation, after the operation a will have even occurrences and b will have odd occurrences, the size of O is unchanged. The operation is thus corresponding to moving black piece from section of a to empty section of b. The similar thing holds when a has even occurrences and b has odd occurrences before the operation.

If both a and b appeared an odd number of times before the operation, after the operation they both have even occurrences, the size of O decreases by 2. The operation is thus corresponding to removing 2 adjacent black pieces a and b.

To solve the original problem, we will solve an equivalent problem on the ring: find the minimum number of operations to make the ring contain at most 1 black piece. There are 3 operations we could make: putting 2 new black pieces at 2 adjacent empty sections; moving 1 black piece to an adjacent empty section; removing 2 adjacent black pieces.
Greedy
As we are trying to reduce the number of black pieces, we won’t make operations that increase the number of black pieces (by 2). We can only remove 2 adjacent black pieces, so we need to use moving operations to move some 2 black pieces to some 2 adjacent sections and then remove them.
Suppose there are 4 black pieces a–b–c–d listed in the clockwise order. It is non-optimal if we remove pair (a, c) and pair (b, d), or pair (a, d) and (b, c) as the moving operations needed will be bigger than when removing pair (a, b) and (c, d).
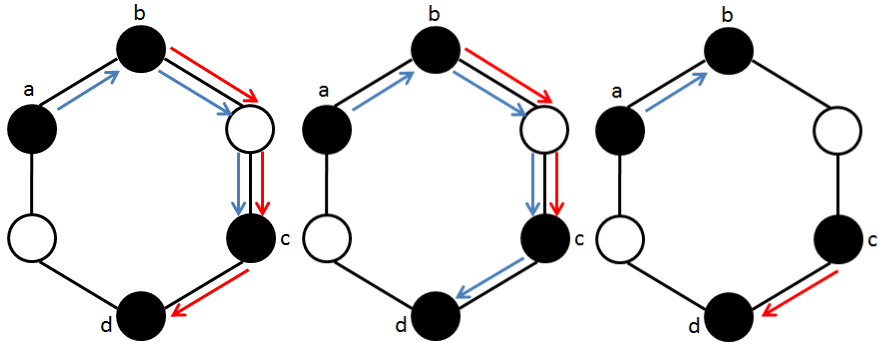
We can prove that in an optimal solution, no 2 pairs of 2 removing black pieces will “intersect”, because if that happens we can always make them “non-intersect” with even less operations.
When |O| is even
There are only 2 cases. For each case calculate the operations needed and take the smaller one.

When |O| is odd
In this case there will be 1 black piece remaining on the ring in the end. Just try all possibility of it, ignore it and we will continue solve as in the case |O| is even above.
Implementation:
import java.io.*;
import java.util.*;
public class NearPalindromesDiv1 {
int diff(int x, int y) { return Math.min( Math.abs(x - y), 26 - Math.abs(x - y) ); }
int go(ArrayList<Integer> a, int start_idx, int step) {
int i = start_idx, res = 0;
while (step > 0) {
step--;
res += diff(a.get(i), a.get( (i + 1) % a.size() ));
i = (i + 2) % a.size();
}
return res;
}
public int solve(String s) {
ArrayList<Integer> a = new ArrayList<Integer>();
for(int i = 0; i < 26; ++i) {
int occ = 0;
for(int j = 0; j < s.length(); ++j)
if (s.charAt(j) - 'a' == i) occ += 1;
if (occ % 2 == 1) a.add(i);
}
if (a.size() <= 1) return 0;
int k = a.size() / 2;
int res = go(a, 0, k);
for(int i = 1; i < a.size(); ++i) res = Math.min(res, go(a, i, k));
return res;
}
}
Div1Medium: RandomDijkstraDiv1
Let C be the number of ordering of N nodes such that when N nodes are removed from S in this order, the distance array D[] will be correctly computed. The probability we need to find will be C / N! where N! = 1 * 2 * .. * N is the number of all possible ordering of N nodes.
Dynamic programming approach
Since the constraint is small (N <= 14), an experienced participant can see that counting C can be approached by dynamic programming method in which we will simulate the Dijkstra algorithm by keep track for each node 2 information: is it removed from S or not yet, is its D[] corrected or not yet. However, this may cause 4^N states in total which is too much. To reduce the number of states, we need to know some properties of the Dijkstra algorithm.
What are the conditions for D[v] to be corrected?
Let prev(v) denote the set of all nodes u such that there exists a shortest path from 0 to v in which it visits u just immediately before v.
Lemma: In the end of the random Dijkstra algorithm, D[v] will be corrected if and only if there exists a node u in prev(v) such that D[u] were already corrected at the moment u was removed from S.
Reducing the number of DP states
Based on the lemma above, to check if all D[] will be corrected when the random Dijkstra algorithm terminates or not, for nodes were removed from S we only need to care if their D[] were already corrected at the moment they were removed or not. We don’t need to know D[] of nodes that are not removed from S yet.
Therefore, state of each node will be one of the following:
- It is not removed from S yet.
- It was removed from S and its D[] were already corrected at the moment it was removed.
- It was removed from S and its D[] were not corrected at the moment it was removed.
Now we have reduced the number of states down to 3^N which is small enough for N <= 14.
The transition of DP
The state of N nodes can be represented by a number of N digits written in base 3 (whose value in base 10 will be in range [0, 3^N – 1] ) where each digit will describe the current state of each node.
Let dp(X) be the number of ways of removing nodes from S such that we can reach state X where X is a number in base 3 that describes the current state of N nodes. Following is a way of computing the dp() table using a bottom-up approach. Suppose dp(X) is already computed.
- From X, we know the set Y of nodes which were not removed from S yet. The next node removed from S should be one node in Y. Based on the above lemma and state of removed nodes, for each node u in Y we will know if D[u] is already corrected or not yet.
- For each node u in Y, consider removing it from S next.
- When u is removed, the new state of N nodes, denoted by X’, can be determined. By the counting principle rules of sum, dp(X’) will increase by dp(X).
So the entire dp() table can be computed in O(3^N * N) since each transition takes O(N). You can see the full implementation below for details.
Implementation:
import java.io.*;
import java.util.*;
public class RandomDijkstraDiv1 {
static int INF = (int)(1e9);
int n;
int cost[][];
int pow3[], dist[];
// do bellman ford to find shortest path from 0 to others, it's shorter than Dijkstra :))
void bellman_ford() {
dist = new int[n]; Arrays.fill(dist, INF); dist[0] = 0;
for(int k = 0; k < n; ++k) {
for(int i = 0; i < n; ++i)
for(int j = 0; j < n; ++j)
if (dist[j] > dist[i] + cost[i][j])
dist[j] = dist[i] + cost[i][j];
}
}
// check whether there exists a shortest path of the form 0->...->u->v
boolean sp_prev(int u, int v) { return dist[v] == dist[u] + cost[u][v]; }
// get the digit at n-th position in base 3 representation of x
int base3_digit(int x, int n) { return (x / pow3[n]) % 3; }
public double solve(int _n, int[] g) {
n = _n;
// transform g to 2D array cost for convenience
cost = new int[n][];
for(int i = 0; i < n; ++i) {
cost[i] = new int[n];
for(int j = 0; j < n; ++j) cost[i][j] = g[i * n + j];
}
bellman_ford();
boolean ok_dist[][] = new boolean[(1 << n)][];
for(int mask = 0; mask < (1 << n); ++mask) {
ok_dist[mask] = new boolean[n];
// mask : set of removed vertex such that its D[] is already corrected at the moment it was removed
// ok_dist[mask][i] = true iff D[i] will be corrected
ok_dist[mask][0] = true; // D[0] always corrected
for(int i = 0; i < n; ++i)
if ( ((mask >> i) & 1) == 1 ) {
for(int j = 1; j < n; ++j)
if (sp_prev(i, j) == true) ok_dist[mask][j] = true;
}
}
pow3 = new int[n + 1];
pow3[0] = 1; for(int i = 1; i <= n; ++i) pow3[i] = pow3[i - 1] * 3;
long dp[] = new long[ pow3[n] ];
// 2 : unremoved, 1 : removed + its D[] already corrected at the moment it removed, 0 : removed + its D[] not corrected at the moment it removed
dp[ pow3[n] - 1 ] = 1; // initially, all was not removed
// do a bottop-up dp
long tot = 0;
for(int cur = pow3[n] - 1; cur >= 0; --cur) {
if (dp[cur] == 0) continue;
int mask = 0; // mask is the set of vertices that were removed and their D[] is corrected at the moment they were removed
for(int i = 0; i < n; ++i) if (base3_digit(cur, i) == 1) mask += (1 << i);
boolean digit_2 = false;
for(int u = 0; u < n; ++u) {
if (base3_digit(cur, u) == 2) { // if vertex u is unremoved ==> now try to remove it
digit_2 = true;
int next = cur - pow3[u]; // change state of u from 2 to 1
if (ok_dist[mask][u] == false) next -= pow3[u]; // D[u] not corrected yet, change state of u from 1 to 0
dp[next] += dp[cur];
}
}
if (digit_2 == false) { // all vertices were removed
boolean all_dist_ok = true;
for(int i = 0; i < n; ++i)
if (base3_digit(cur, i) == 0)
if (ok_dist[mask][i] == false) {
all_dist_ok = false; break;
}
if (all_dist_ok == true) { // all D[] are corrected in the end
tot += dp[cur];
}
}
}
// calculate the probabilty
long fact = 1; for(int i = 1; i <= n; ++i) fact *= i;
double res = (double)(tot) / fact;
return res;
}
}
Div1Hard: BinarySearch
Firstly, let’s build a binary tree T that corresponds to the binary search procedure. This tree can be define recursively as follows:
- This tree T will “manage” all elements with indices in range [0, N – 1] of the permutation P. In other words, this tree will “manage” the entire permutation P.
- A tree that “manage” all elements with indices in range [L, R] will has root with key P[mid] where mid = (L+R)/2, its left branch will be a tree that “manage” all elements with indices in range [L, mid – 1], its right branch will be a tree that “manage” all elements with indices in range [mid +1, R].
An example of this binary tree T when N = 15 is shown in the figure below:

For now, we will assume this tree T is a perfect binary tree (that is, N = 2^k – 1 for some k).
Re-define binary search procedure based on T
The binary search procedure binary_search(P, v) can be interpreted as follows. First, the search will look at the root of T, compare its key with the searched value v. If its key = v, return “1”. If its key > v, we go down to the left branch of it and continue doing similarly. If its key < v, we go down to the right branch of it and continue doing similarly. Once we can’t go to left/right branch, the search terminates and returns “0”.
Counting P by counting T instead
Obviously there is a 1-1 correspondence between the permutation P and the binary tree T, so we can count T instead.
We will put the N key values 0, 1, 2, …, N in this order to the tree T. We will count the number of ways of putting these key values such that the tree T is consistent with the signature string S.
Each time we put a key value to a node, we will color that node black. Initially all N nodes of T are white. That means, black nodes are occupied nodes, white nodes are empty nodes. Assume we have already put i keys with values 0, 1, …, i – 1 to T. Now we are trying to put the key value i to the tree such that 2 following conditions must satisfied:
- We can only put the key value i to a white node
- The location of the key value i must consistent with binary_search(P, i)
The condition 1) is easy to deal with but the condition 2) is much harder!
Dealing with condition 2)
The procedure binary_search(P, i) will start by examining the root of the tree T.
- If it is black, its key value < i, so the binary search procedure will go down to its right branch and continue doing similarly.
- If it is white, suppose we won’t put the key value i in this node, then this node is reserved for a key > i, so the binary search procedure will go down to its left branch and continue doing similarly.
In the end, we will obtain a path A which starts from the root of T and ends at a leaf of T. We have an important lemma:
Lemma: binary_search(P, i) will return “1” if and only if the key value i is put to any white node on the path A.

Let’s call path A as the “potential path”. The “potential path” A can be uniquely determined by its leaf, we will refer to this leaf by calling it node A. So, node A is the leaf lying on the “potential path” A. As we are putting N key values to tree T, the leaf of “potential path” will move from left to right.
Dynamic programming approach
The lemma above suggests that we can use dynamic programming approach in which we will keep track the “potential path” A to deal with condition 2). Let’s analyse how the “potential path” changes over time. When we are putting the key value i to T, there are 2 cases to consider:
Case 1: binary_search(P, i) = 0
In this case, we cannot put the key value i in any white node on the path A. We will do one of the 2 following actions:
- We will postpone putting i in T by temporarily putting this key in a set U instead and continue process key i + 1. Keys in the set U will be put to T later.
- We will put the key i to the left of path A. This will be explained more below.
Case 2: binary_search(P, i) = 1
We must put the key value i to one of white nodes on the path A. Suppose we put i in the white node u, the new “potential path” will be some path A’ in which u is a lowest common node of A and and A’ (otned that node A belongs to u’s left brach, while node A’ belongs to u’s right brach).
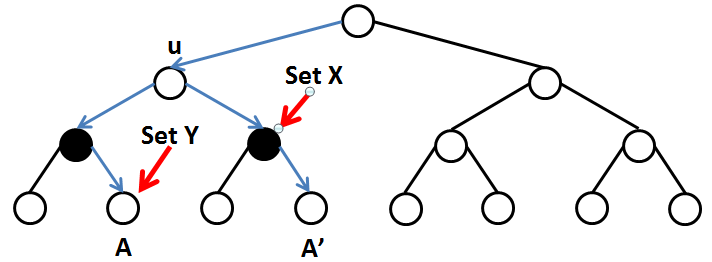
Let X be the set of nodes on the path from node u to node A’ which follows by a right turn. Clearly nodes in X must be black. It’s time to use keys in the set U, because black nodes are occupied nodes. We should choose |X| keys from U and putting them in |X| nodes from X.
Let Y be the set of white nodes on the path from node u to node A. These nodes in set Y must be reserved for key values > i. Keys in set U cannot be put to these nodes because if we do this, path A cannot be a “potential path”. So, later, when we are putting key value j (j > i) where binary_search(P, j) = 0, we can put j to one of nodes in set Y (action b the case 1 above).
State of DP
After the analysis above, the exact DP state started to emerge. We will applied dynamic programming with state (A, size_U, size_Y) where:
- A is the current “potential path”. There are O(N) such paths.
- size_U is the number of keys that are still in the set U. Clearly 0 <= size_U <= N
- size_Y is the number of nodes in the set Y that doesn’t have a key yet. Clearly 0 <= size_Y <= N.
We will compute a table dp() where dp(A, size_U, size_Y) is the number of ways of putting keys into T to reach state (A, size_U, size_Y).
The transition of DP
Assume we are at state (A, size_U, size_Y) and we are putting key value i into the tree T. There are 2 cases to be consider, as above have mentioned:
Case 1: binary_search(P, i) = 0
In this case, we cannot put the key value i in any white node on the path A. We can do one of the 2 following actions:
- We will postpone putting i in T by temporarily putting this key in the set U instead and continue processing key i + 1. From the current state (A, size_U, size_Y) we reach state (A, size_U + 1, size_Y). dp(A, size_U + 1, size_Y) will increase by dp(A, size_U, size_Y).
- We will put the key i to one of nodes in the set Y on the left of path A. There are size_Y ways of choosing a node for i. From the current state (A, size_U, size_Y) we reach state (A, size_U, size_Y – 1). dp(A, size_U, size_Y – 1) will increase by dp(A, size_U, size_Y) * size_Y.
Case 2: binary_search(P, i) = 1
We must put the key value i to one of white nodes on the path A. Try all possibility of u and A’, for each possibility we do the following:
- Determine 2 sets X and Y
- Choose |X| keys from size_U keys currently in the set U to put them into |X| nodes in X. There are C(size_U, |X|) ways to choose |X| keys and |X|! ways of putting them, thus there are C(size_U, |X|) * |X|! ways in total.
- size_Y will increase by |Y|.
- From the current state (A, size_U, size_Y) we reach state (A’, size_U – |X|, size_Y + |Y|). dp(A’, size_U – |X|, size_Y + |Y|) will increase by dp(A, size_U, size_Y) * C(size_U, |X|) * |X|!.
For each key value i, the dp() table will be computed in O(N^4), as there are O(N^3) states and it takes O(N) for each transition. So the algorithm has complexity of O(N^5).
Some tricky details
The algorithm above is not completed yet. There are some corner cases you should consider.
The first one is that the node A of “potential path” A can be white or black. We need to add a dimension of size 2 to the dp state to know the current color of node A.
The second one is when T is not a perfect binary tree. In this case, “potential path” may not end at some leaf (but end at parent of some leaf instead).
Implementation:
import java.io.*;
import java.util.*;
public class BinarySearch {
static int MOD = (int)(1e9) + 7;
int n;
int[] left_child, right_child, depth, go_left, go_right;
boolean[][] is_anc;
int build_binsearch_tree(int from, int to, int cur_depth, int left_cnt, int right_cnt, boolean[] mark) {
if (from > to) return -1;
if (from == to) {
left_child[from] = right_child[from] = -1;
depth[from] = cur_depth; go_left[from] = left_cnt; go_right[from] = right_cnt;
for(int i = 0; i < n; ++i)
if (mark[i] == true) is_anc[from][i] = true;
return from;
}
int mid = (from + to) / 2;
for(int i = 0; i < n; ++i)
if (mark[i] == true) is_anc[from][i] = true;
mark[mid] = true; depth[mid] = cur_depth; go_left[mid] = left_cnt; go_right[mid] = right_cnt;
left_child[mid] = build_binsearch_tree(from, mid - 1, cur_depth + 1, left_cnt + 1, right_cnt, mark);
right_child[mid] = build_binsearch_tree(mid + 1, to, cur_depth + 1, left_cnt, right_cnt + 1, mark);
mark[mid] = false;
return mid;
}
void add(int[][][][][] dp, int i, int j, int k, int t, int u, int val) {
dp[i][j][k][t][u] = (dp[i][j][k][t][u] + val) % MOD;
}
int mul(int a, int b) { return (int)( ((long)(a) * b) % MOD); }
public int count(String s) {
n = s.length();
left_child = new int[n]; right_child = new int[n];
depth = new int[n]; go_left = new int[n]; go_right = new int[n];
is_anc = new boolean[n][n];
build_binsearch_tree(0, n - 1, 0, 0, 0, new boolean[n]);
int[] fact = new int[n + 1];
fact[0] = 1; for(int i = 1; i <= n; ++i) fact[i] = mul(fact[i - 1], i);
int[][] binom = new int[n + 1][n + 1];
for(int i = 0; i <= n; ++i) { binom[i][0] = binom[i][i] = 1; binom[i][1] = i; }
for(int i = 3; i <= n; ++i)
for(int j = 2; j < i; ++j) binom[i][j] = (binom[i - 1][j] + binom[i - 1][j - 1]) % MOD;
int[][][][][] dp = new int[2][n][2][n + 1][n + 1];
int cur = 0, nxt = 1;
int left_most = 0; for(int i = n - 1; i >= 0; --i) if (left_child[i] == -1) left_most = i;
int right_most = 0; for(int i = 0; i < n; ++i) if (right_child[i] == -1) right_most = i;
dp[cur][ left_most ][0][0][0] = 1;
for(int v = 0; v < n; ++v) {
// init for dp[nxt]
for(int leaf = 0; leaf < n; ++leaf)
for(int leaf_occupied = 0; leaf_occupied < 2; ++leaf_occupied)
for(int owed0 = 0; owed0 <= n; ++owed0)
for(int unused0 = 0; unused0 <= n; ++unused0) dp[nxt][leaf][leaf_occupied][owed0][unused0] = 0;
// bottom-up to update dp[nxt]
for(int leaf = 0; leaf < n; ++leaf)
for(int leaf_occupied = 0; leaf_occupied < 2; ++leaf_occupied)
for(int owed0 = 0; owed0 <= n; ++owed0)
for(int unused0 = 0; unused0 <= n; ++unused0) {
int cur_state = dp[cur][leaf][leaf_occupied][owed0][unused0];
if (cur_state == 0) continue;
if (s.charAt(v) == '0') {
// case 1: use this 0 to pay
if (owed0 >= 1)
add(dp, nxt, leaf, leaf_occupied, owed0 - 1, unused0, mul(cur_state, owed0) );
// case 2: this 0 will be use later
if (unused0 + 1 <= n)
add(dp, nxt, leaf, leaf_occupied, owed0, unused0 + 1, cur_state);
continue;
}
// s[v] = '1'
// case 1: leaf is unoccupied, put v at leaf
if (leaf_occupied == 0) {
if (right_child[leaf] == -1) add(dp, nxt, leaf, 1, owed0, unused0, cur_state);
else {
add(dp, nxt, right_child[leaf], 0, owed0, unused0, cur_state);
if (unused0 >= 1) add(dp, nxt, right_child[leaf], 1, owed0, unused0 - 1, mul(unused0, cur_state));
}
}
// case 2: put v at u which is an ancestor of leaf
for(int u = leaf + 1; u < n; ++u)
if (is_anc[leaf][u] == true) {
int borrow0 = go_left[leaf] - go_left[u] - 1 + (1 - leaf_occupied);
if (owed0 + borrow0 > n) continue;
for(int nxt_leaf = u + 1; nxt_leaf < n; ++nxt_leaf)
if (is_anc[nxt_leaf][u] == true && left_child[nxt_leaf] == -1) {
int use0 = go_right[nxt_leaf] - go_right[u] - 1;
// case 2a: nxt_leaf is unoccupied
if (use0 <= unused0) {
int add = mul( mul( binom[unused0][use0], fact[use0] ), cur_state);
add(dp, nxt, nxt_leaf, 0, owed0 + borrow0, unused0 - use0, add);
}
// case 2b: nxt_leaf is occupied
if (use0 + 1 <= unused0 && right_child[nxt_leaf] == -1) {
int add = mul( mul( binom[unused0][use0 + 1], fact[use0 + 1] ), cur_state);
add(dp, nxt, nxt_leaf, 1, owed0 + borrow0, unused0 - use0 - 1, add);
}
}
}
}
int tmp = cur; cur = nxt; nxt = tmp;
}
int res = 0;
for(int unused0 = 0; unused0 <= n; ++unused0)
res = (res + mul(dp[cur][right_most][1][0][unused0], fact[unused0]) ) % MOD;
return res;
}
}
laoriu
Guest Blogger


