November 28, 2019 Single Round Match 771 Editorials
BagsOfMarbles
Consider the worst case:
- a bag with no black marbles contains bagSize white marbles
- a bag with no white marbles does not matter
- a bag with some white marbles contains one white marble
- a bag with some black marbles contains only black marbles, and thus does not matter
Thus, we can guarantee that we have enough white marbles if and only if the desired number is at most bagSize * noBlackBags + someWhiteBags.
When actually picking up the white marbles we need, it’s always optimal to start with no-black bags (each marble we take is white) and only then to use the some-white bags (where in the worst case we first take bagSize-1 black marbles and then one white).
Code:
public int removeFewest(int desired, int bagSize, int noWhiteBags,
int noBlackBags, int someWhiteBags, int someBlackBags)
{
int guaranteedWhiteBalls = bagSize * noBlackBags + someWhiteBags;
if (guaranteedWhiteBalls < desired) return -1;
if (desired <= bagSize * noBlackBags) return desired;
int answer = bagSize * noBlackBags;
desired -= answer;
return answer + desired * bagSize;
}
CollectAllCoins
First, suppose the number of columns is odd.
We can clearly pick up the entire first row of coins, left to right:
HTTTTTT
TTTTTTT -> HHHHHHH
TTTTTTT TTTTTTT
TTTTTTT TTTTTTT
Can we now pick up the entire second row? Not directly, left-to-right, because once we pick up the leftmost coin, its neighbor will flip from heads back to tails. As we go left to right, we can only pick up every second coin.
HTTTTTT
TTTTTTT -> HHHHHHH -> H H H
TTTTTTT TTTTTTT HTHTHTH
TTTTTTT TTTTTTT TTTTTTT
This looks great. Each coin in the topmost row got toggled twice, so they are back heads up and we can pick them up in a second pass.
HTTTTTT
TTTTTTT -> HHHHHHH -> H H H ->
TTTTTTT TTTTTTT HTHTHTH HHHHHHH
TTTTTTT TTTTTTT TTTTTTT TTTTTTT
And as this has brought us to the same situation with one fewer rows, we can simply repeat the above process until we pick up everything.
If the number of rows is odd, we can do the same thing but row-by-row instead of column-by-column. Probably the easiest implementation is to swap R and C, solve the task using the solution described above, and then to transpose the answer we got.
Finally, it turns out that if both R and C are even, there is no solution. During the contest it was sufficient to play around with small patterns and to make an educated guess, but for the sake of completeness we include a proof of this fact.
Imagine a grid where the coins are at vertices and edges correspond to adjacency. Take a red pen. Each time you remove a coin, color red all the edges that now have both vertices without a coin.
The first coin is special: when you remove it, you don’t color anything red yet.
For each other coin (let’s call these ordinary coins), the number of red edges you’ll paint must be odd. (The coin starts tails, it must be heads when it is removed, so an odd number of its neighbors must have been removed before this coin was removed.)
There are R*C-1 ordinary coins. If both R and C are even, this number is odd. Thus, if it was possible to win the game, we would remove an odd number of ordinary coins, and for each of them we would draw an odd number of red edges. Thus, the total number of red edges we would draw would be odd.
However, we can easily realize that when we win a game, all edges of the entire grid must be drawn in red (each exactly once). The grid has R(C-1) + C(R-1) edges, and for R, C even this number is even. Thus, it is not possible to win the game if both R and C are even.
int[] solve(int R, int C) { // assumes C is odd
int[] answer = new int[R*C];
int idx = 0;
for (int c=0; c<C; ++c) answer[idx++] = c;
for (int r=1; r<R; ++r) {
for (int c=0; c<C; c+=2) answer[idx++] = r*C+c;
for (int c=1; c<C; c+=2) answer[idx++] = r*C+c;
}
return answer;
}
public int[] collect(int R, int C) {
if (R%2 == 0 && C%2 == 0) return new int[0];
if (C%2 == 1) return solve(R,C);
int[] almost = solve(C,R);
int[] answer = new int[R*C];
for (int i=0; i<R*C; ++i) {
int r = almost[i]%R, c = almost[i]/R;
answer[i] = r*C + c;
}
return answer;
}
Addendum: There are also other patterns that can be used in the cases when at least one of R and C is odd. For example, if C is odd, you can first pick up the first row, then column 0 top to bottom, column 2 top to bottom, column 4 top to bottom, …, and after you finish all even-numbered columns you can pick up all odd-numbered ones in the same way.
AllEven
This is a counting problem and the answers are rather large, so it screams “dynamic programming”. We have to come up with a clever way of counting multiple numbers at the same time.
The crucial observation is that when you are building a number (i.e., a sequence of digits), all information we need about it is its length (which is less than 20) and for each digit a single bit of information: do we currently have an odd or an even number of pieces of this digit?
Let dp[x][y] be the number of strings of digits of length x such that the bitmask y represents those digits that have an odd number of occurrences. For example, dp[8][0000000110_2] counts the strings of length 8 that have an odd number of 1s, odd number of 2s, and an even number of each other digit. (Note that these strings can start with a zero.)
These values are easy to precompute: dp[0][0] = 1, and for x > 0 we have that dp[x][y] is simply the sum of dp[x-1][y with bit d toggled] over d = 0..9.
Once we have these values, we can easily implement a function that will take an integer N and count the good numbers in the half-open range [0,N). One possible way looks as follows:
- Determine L = the number of digits in N.
- For each length i < L, count all good numbers of length i. This can be done e.g. by trying all possibilities for the first digit (d=1..9) and then adding dp[i-1][only bit d is on].
- Count the good numbers of length L that are less than N. This can be done by trying all possibilities for the length of the prefix the number shares with N, and all possibilities for the next digit (which has to be smaller than the corresponding digit in N, and it has to be at least 1 if it’s the leading digit).
TwoMonthScheduling
This is also a dynamic programming problem, but this time we will need to do some optimization as well.
For x < y, let dp[x][y] = minimum time to complete first y jobs if we do the second month of exactly the last y-x of them during last month (or infinity if we cannot do that at all). The solution to the task is then the minimum of dp[x][all jobs].
Before we start actually computing the dp[][] values, we’ll do one more thing: precompute the prefix sums for the two input arrays. That way we can take any range of jobs and in constant time determine the total number of workers they require each month.
When computing dp[y][z], we have the following options:
- During the penultimate month we do only the first month of the last z-y jobs and nothing else. In this case the number of months we’ll need is 2 + minimum of dp[*][y].
- During the penultimate month we also do the second month of the immediately preceding x-y jobs, for some x < y such that we can do all those jobs at the same time. In this case the number of months we’ll need is 1 + dp[x][y].
This gives us a solution in O(n^3): we have O(n^2) states and O(n) options to consider for each of them.
However, the above solution can be optimized as follows: Suppose we fix y and compute all dp[y][z] in decreasing order of z. As we decrease z, we decrease the number of jobs done in the last month, which means that the range of valid options for x either remains the same, or increases. Thus, each time we decrease z, we update the range of valid options for x and update the minimum solution produced by any of them.
After this update, we can evaluate all the states dp[y][*] in O(n) time, bringing the total time complexity down to O(n^2).
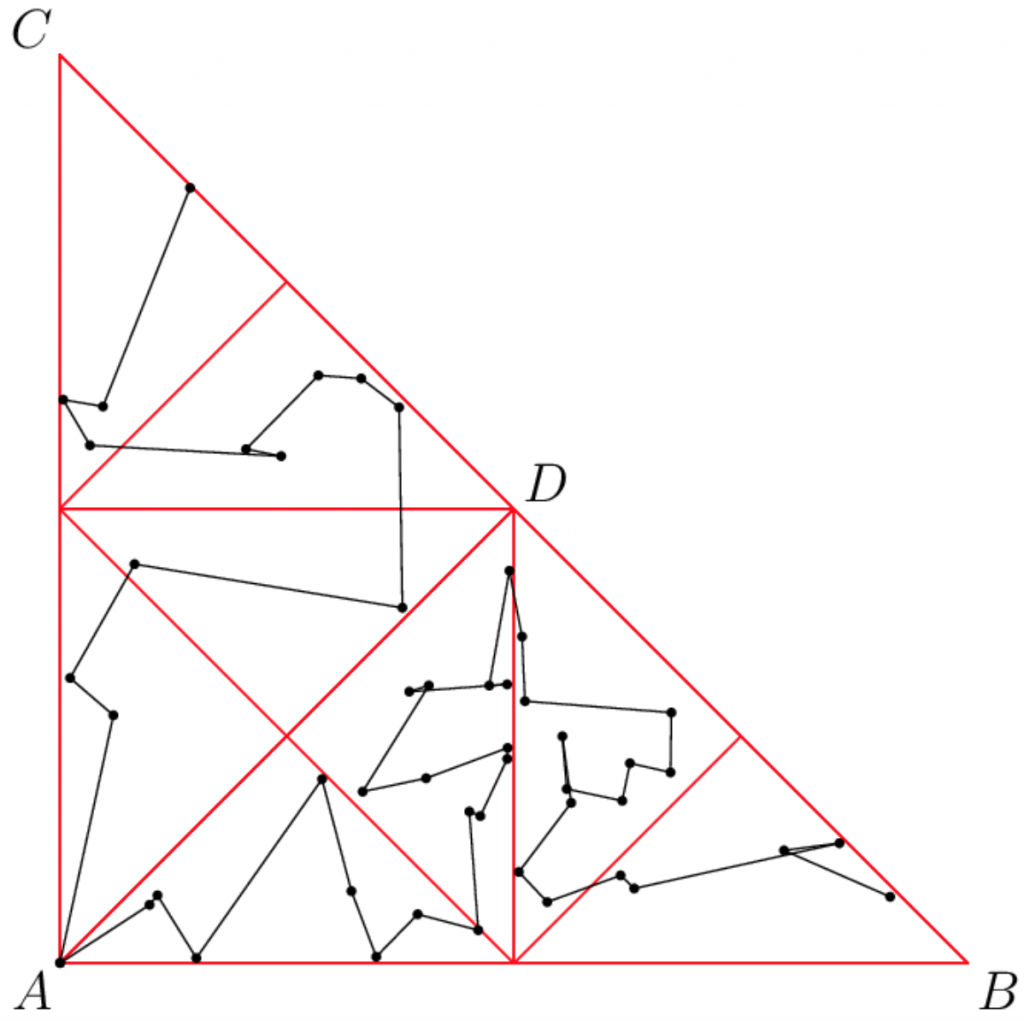
TrianglePath
This geometry problem gives you some freedom when constructing your solution, so it’s possible to solve it using some local optimization techniques — if implemented well, they converge quickly. (Which is why I didn’t use this problem in a more serious round 😉 ) However, there is also a deterministic solution and a nice proof that it always works. This is explained below.
We can restate the condition as follows: “The sum of squares of segment lengths must be at most equal to the square of the hypotenuse.” Stated this way, it should remind you of the Pythagorean theorem. And indeed, as illustrated in Example 0, when given the three corners of the triangle, the optimal solution is to use both legs of the triangle and then the condition is satisfied exactly.
The main trick in the deterministic solution is as follows: Suppose our triangle is ABC, with the right angle at A and going ccw. Drop an altitude from A onto BC and call its foot D. We have now divided the triangle into two smaller right triangles (both similar to the original one): DCA and DAB. Some of our points are inside DCA, some are not.
Why did we divide the triangle like this? Well, because now we can solve the problem recursively for each of the new triangles. From each of them we will get a polyline at most as long as its hypotenuse: that is, from DCA its length will be at most |AC|^2 and from DAB it will be at most |AB|^2. But the hypotenuses of the new triangles are the legs of the original one — and as the total length is at most |AC|^2 + |AB|^2, it is at most |BC|^2, and we are done.
Two technical notes follow.
First, the base case of the recursion is when all points we have in our triangle are at the same coordinates, and then the construction is trivial.
Second, the analysis above was a bit sloppy. It would be correct if we had a point at A in both of the smaller triangles, as then we could directly concatenate the two partial solutions at that point. What we actually do is we simply connect the last point of one of them to the first point in the other. This is still OK, as the square of the new segment is at most equal to the sum of squares of segments going from those two points to A.
misof


