June 17, 2017 Learning and Understanding Big-O Notation
We’ve all heard of Big(O). It’s something most of us learn in college and promptly forget. We also know it’s something that Top Coders and Googlers are good at and many of us would like to be good at it too!
I can relate – I find many algorithms fascinating and many more intimidating. And for a long time I struggled to get my head around the concept of Big(O). I knew what it was – vaguely – but I had no deep understanding – no intuition for it at all. And I knew that it was important in telling me which algorithms were good and which weren’t.
If you can relate to that then this article is for you – you will be able to understand Big(O) and have the beginnings of an intuition about it.
What is Big(O)?
So what is Big(O)? It simply describes how an algorithm scales with more inputs. Big(O) is an upper-limit on the algorithm ignoring all exceptions, special cases, and complex details and irrelevant constants.
Squint at your algorithm – find it’s important parts (usually the loops) and you’ve trapped the Big-O.
And why is this important? Well, let’s consider a common problem: finding a needle in a haystack. Here are two approaches:
(1) Find the needle in a haystack
for(item in haystack) {
if(item == needle) return item;
}
(2) Find needle in sorted haystack
low = 0
high = sortedhaystack.size - 1
while(low <= high) {
mid = (low + high) / 2;
item = sortedhaystack[mid];
if(item == needle)
return item;
if(item > needle)
high = mid - 1;
else
low = mid + 1;
}
Finding Big(O)
If we “squint” at the algorithm looking at the number of times through the main loops and ignoring all the complications we see that (1) walks through every item of the input. This means that it’s O is directly proportional the number of items in the haystack. If we call the number of items `n` then algorithm (1) has:
![]()
Squinting at algorithm (2) we see that it also has only one loop where it is going from low to high. Now this range again starts off as the number of items in the input but on every loop it halves the range it has to travel by narrowing to the mid-point. This kind of discarding half a range is terribly common and terribly useful. This constant halving means that the loop only goes through ![]() items. Therefore algorithm (2) has:
items. Therefore algorithm (2) has:
![]()
Because we do this halving thing often, it is useful to remember ![]() and its relation to halving in loops.
and its relation to halving in loops.
So now we have some idea about the Big(O)’s. Big deal! How does that help us know which algorithm is better?
Well remember, Big(O) gives us useful information as the algorithm scales. If we have a small haystack then it really doesn’t matter – even if each loop takes a second then a haystack of a few hundred items will finish quickly enough in both cases.
But if we have a million items things get interesting:
Algorithm 1: (1 second per loop)

Algorithm 2: (1 second per loop)
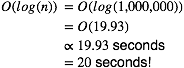
We can see there is a phenomenal difference between the two. So we can see that just knowing the O-class can really help us figure out how an algorithm scales.
Now the million-dollar question is: what are the common O-classes and how do each of them scale?
Meet The Big-O Classes
Let’s take a look at important the Big-O classes now:
The Flash |
Shrinking Violet |
Groot |
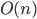
Clark Kent |
 |
 |
 |
 |
The Fastest O |
A common way to shrink inputs quickly by discarding halves |
The Rare One – Rarely found in practice |
A Straight Guy – looking at each input leads to linear scale |
| 1 million items in… 1 second | 1 million items in… 20 seconds | 1 million items in… 16 minutes | 1 million items in… 11 days |
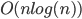
Hisoka the Card Magician |
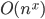
The Power Sisters |
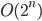
Wonder Woman |
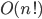
Link the Traveler |
 |
 |
 |
 |
Often reflects a sort |
Growing exponentially – We can usually see `x` nested loops in the algorithm |
Combination Loops – looking at various subsets in the input |
All possible permutations of the inputs |
| 1 million items in… 1 year | 1 million items in… 32,000 years 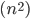 , 32 billion years , 32 billion years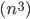 |
1 million items in… 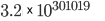 millennia millennia(longer than the universe has been around!) |
1 million items in… 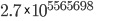 millennia millennia(good grief!) |
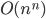
The Blackest Panther |
 |
The worst scaling! |
| 1 million items in………wayyyy too long… |
Taking a deeper look
Let us understand each class and build an intuition for them:
: The Fastest O
|
The holy grail – algorithms always complete in a fixed time irrespective of the size of the input. |
get_first_item(array haystack) {
if(haystack.size > 0)
{
return haystack[0];
}
}
|
|
|
Flash – The Fastest Big-O |
Examples: return the head of a list, insert a node into a linked list, pushing/popping a stack, inserting/removing from a queue… |
| 1 million items in…1 second | |
: Divide and Conquer
|
These algorithms never have to look at all the input. They often halve inputs at each stage and thus have inverse the performance of exponentiation (see the Power-Sisters to contrast). |
binary_jump_search(item needle, array sortedhaystack) {
n = sortedhaystack.size;
jump = n/2;
pos = 0;
while(jump > 0) {
while(pos+jump < n && sortedhaystack[pos+jump] <= needle)
{
pos += jump;
}
jump = jump/2;
}
if(sortedhaystack[pos] == needle)
{
return pos;
}
}
|
|
|
Shrinking Violet – Halving input Big-O |
Examples: looking up a number in a phone book, looking up a word in a dictionary, doing a binary search, find element in a binary search tree, deleting from a doubly-linked list… |
| 1 million items in…20 seconds | |
: The Rare O
|
If we notice that 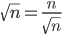 in some sense, in some sense, 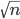 is in the “middle” of is in the “middle” of 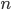 . This type of an algorithm is not very commonly found. . This type of an algorithm is not very commonly found. |
|
Groot – The Rare One |
Examples: Grover’s algorithm, The Square Root Trick |
| 1 million items in…16 minutes | |
: A Common O
|
This is a linear algorithm which scales directly proportional to the input. This is commonly the case because we often have to access an item at least once. |
find_in_unsorted(item needle, array haystack) {
for(item in haystack)
{
if(item == needle)
{
return item;
}
}
}
|
|
|
Clark Kent – Just a Straight Guy |
Examples: finding the maximum/minimum of a collection, finding the max sequential sum, traversing a linked list, deleting from a singly-linked list,… |
| 1 million items in…11 days | |
: A Sorting O
|
Efficient general sorting algorithms work in time, and many algorithms that use sorting as a subroutine also have this time complexity. It can be shown that algorithms that need to compare elements cannot sort faster than this (Algorithms like counting sort and radix sort use other information and can be faster). |
merge_sort(list items) {
if(items.size <= 1){
return items;
}
mid = items.size / 2;
left_half = items[0:mid];
right_half = items[mid:items.size];
left_half = merge_sort(left_half)
right_half = merge_sort(right_half)
while(left_half and right_half has items)
{
if(first(left_half) <= first(right_half))
{
result.append(pop(left_half));
}
else
{
result.append(pop(right_half));
}
}
if(left_half has items)
{
result.append(left_half);
}
else if(right_half has items)
{
result.append(right_half);
}
}
|
|
|
Hisoka – The Card Magician |
Examples: Merge Sort, Quick Sort, Heap Sort |
| 1 million items in…1 year | |
: The Power O’s
|
These algorithms grow as an polynomial of the input. 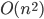 are known as Quadratic and are known as Quadratic and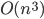 are known as Cubic algorithms. Higher powers are just known as bad algorithms 🙂 . The powers usually reflect the number of nested loops in the system.Note that whenever there are multiple Big-O’s in an algorithm, the biggest class wins out because it usually dominates the scaling. We can see this in the example below which has both (two nested loops) and (three nested loops) but it’s overall Big-O is are known as Cubic algorithms. Higher powers are just known as bad algorithms 🙂 . The powers usually reflect the number of nested loops in the system.Note that whenever there are multiple Big-O’s in an algorithm, the biggest class wins out because it usually dominates the scaling. We can see this in the example below which has both (two nested loops) and (three nested loops) but it’s overall Big-O is We can see this by noticing the time that smaller classes like take in comparison with larger classes like |
find_max_seq_sum(array numbers) {
max_sum = 0;
for(i = 0;i < numbers.size;i++)
{
curr_sum = 0;
for(j = i;j < numbers.size;j++) { curr_sum += numbers[j]; if(curr_sum > max_sum) max_sum = curr_sum;
}
}
// paranoid check - did we get it right?
chk_sum = 0;
for(i = 0;i < numbers.size;i++)
{
for(j = i;j < numbers.size;j++)
{
curr_sum = 0;
for(k = i;k < j;k++) { curr_sum += numbers[k]; } if(curr_sum > chk_sum)
{
chk_sum = curr_sum;
}
}
}
assert(curr_sum == max_sum);
return max_sum;
}
|
|
|
The Power Sisters – Growing Exponentially |
Examples: : multiplying two n-digit numbers by a simple algorithm, adding two n×n matrices, bubble sort, insertion sort, number of handshakes in a room…: multiplying two n×n matrices by a naive algorithm… |
| 1 million items in… 32,000 years 32 billion years |
|
: Combination O
|
These are exponential algorithms whose growth doubles with every new addition to the input. Algorithms with are often recursive algorithms that solve a problem of size by recursively solving two problems of size 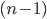 . Another such type is one that iterates over all subsets of a set.If you find it hard to understand how iterating over subsets translates to, imagine a set of switches, each of them corresponding to one element of a set. Now, each of the switches can be turned on or off. Think of “on” as being in the subset and “off” being not included. Now it should be obvious that there are . Another such type is one that iterates over all subsets of a set.If you find it hard to understand how iterating over subsets translates to, imagine a set of switches, each of them corresponding to one element of a set. Now, each of the switches can be turned on or off. Think of “on” as being in the subset and “off” being not included. Now it should be obvious that there are 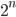 combinations. combinations. |
solve_hanoi(N, from_peg, to_peg, spare_peg){
if (N<1) return; if (N>1)
{
solve_hanoi(N-1, from_peg, spare_peg, to_peg);
}
print "move from " + from_peg + " to " + to_peg;
if (N>1)
{
solve_hanoi(N-1, spare_peg, to_peg, from_peg);
}
}
|
|
|
Wonder Woman – Combination Loops |
Examples: Tower of Hanoi, Naive Finonacci Calculation, … |
| 1 million items in… millennia (longer than the universe has been around!) |
|
: Permutation O
|
This algorithm iterates over all possible combinations of the inputs. |
travelling_salesman(list cities) {
best_path = path(cities);
while(get_next_permutation(cities))
{
if(path(cities) < min_path)
{
best_path = path(cities);
}
}
return best_path;
}
|
|
|
Link – The Traveler |
Examples: The traveling salesman problem. |
| 1 million items in… millennia (good grief!) |
|
: The Slowest O
|
This is just included for fun… Such an algorithm will not scale in any useful way. |
|
The Blackest Panther – Black Hole Black |
Examples: Please don’t find any… |
Did this help you understand Big-O better? Which is your favourite Big-O class? Let me know what you think!
charles.lobo
Guest Blogger

