|

If you have been involved with computer science for any length of time, you have probably heard the term "relational database," but you might not have had the opportunity to actually work with this type of technology. Clearly, relational databases comprise a huge topic, and there are many great books written on the subject. However, the purpose of this article is to give you a chance to learn some database basics and get a better understanding of some of the key components of relational databases.
The intended audience for this article is people who have little or no experience with relational databases, or those who have not worked with databases for a while and would like a refresher course. Even if you're a database expert and don't need a refresher, though, hopefully the section on loading TopCoder RSS feeds to Oracle might be helpful to you.
I. Introduction
Why even bother learning about relational databases? For one thing, many jobs in software development involve working with relational databases. In fact, if the company you work for, or want to work for, has data that they care about then there is a very good chance that the data is stored in a relational database. Sooner or later, you will probably be writing software that interacts with that database, so database skills can be an excellent asset to have in your toolbox.
Besides being a nice resume addition, though, there are many other great reasons to learn about relational databases. XML files are great for storing data in a uniform format that you can access with languages such as JAVA. However, when you start dealing with 20 million records, working with raw XML files can become impractical very quickly. A database, when tuned properly, can help you find the one record you need out of 20 million in seconds, or even less. Besides offering fast access to data, the database can help ensure the integrity of that data. Think about a person who goes to the bank to withdraw money. What if, at the moment the money is being withdrawn from their account, the computer server that houses the database with their account information crashes? Well, if you are using a relational database and have the withdrawal logic wrapped in a "transaction" (we will discuss this in a later article), then you can rest assured that you can get that database back to a point in time right before the crash, with the data intact. (This is assuming, of course, that you have set up a proper database infrastructure and are running the database in ARCHIVELOG mode so that you can reapply all the “transactions” since the last backup.)
While the basic concepts behind relational databases are pretty much universal, in this article we will focus on Oracle. In addition to Oracle holding the top share of the relational-database market (at least according to Wikipedia), TopCoder has recently had some component competitions for Oracle PL/SQL components. If you are in the job hunt, or are just looking to earn some extra money in component competitions, it is probably the single most beneficial database you can learn.
II. Environment Setup
To follow along with the examples in this article, you will need your own "sandbox" database that you will be able to play with. In this article, we will be using Oracle Express Edition, a free download which runs on Windows and several versions of Linux. Oracle Express Edition is ideal for developers who want to learn about Oracle (or in our case, databases in general). The installation is pretty straightforward, at least on Windows XP, though I have not installed the Linux version. You will need to sign up for an Oracle Technology Network account, also free, to be able to download the software. Note that if you already have an Oracle client installed on your machine, installing Oracle Express Edition could interfere with your existing installation. For simplicity's sake, we're going to assume you are installing on a machine without any previous Oracle installations.
Note that when you install the software, you will be prompted for a password to use for the system account. In the examples that follow, we will assume you used a password of oracle. If you use something different during the install then just plug in the appropriate value.
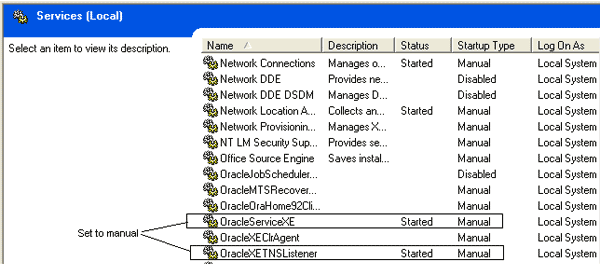
I recommend that you set the Oracle services startup type to manual if you are running on Windows, as this will prevent the services from consuming a lot of memory when you are not using Oracle. To set the services to manual startup, go to Start->Run and type services.msc. You should get a dialog box similar to the one shown below. Find the OracleServiceXE and OracleXETNSListener services, right-click on each, and select "properties." You can then set the startup type to manual. Note that you will need to start these services up whenever you want to use Oracle on your machine. Alternatively, you can just go to Start->Programs->Oracle 10g Express Edition->Start Database/Stop Database to start/stop the database.
III. Tables
Tables in relational databases are pretty straightforward. A table is just a set of data elements that we want to store. You can think of a table as a two-dimensional array, where the rows represent the actual data and the columns are what the data values are called. So if we were making a database table based off of the active algorithm coder list, here is how our table might look (note that the data here is totally fictitious):
| coder_id | handle | country_name | alg_rating | alg_vol | alg_num_ratings |
| 123456 | slowpoke | United States | 1020 | 320 | 42 |
| 123457 | fastcoder | China | 1941 | 100 | 13 |
An important component of a database table is the primary key. The primary key is the column or set of columns within each row of the table that make that row unique from all the other rows in the table. So in our table above, we would make the primary key on coder_id, since that value should always be unique for each row in this table. In situations where there is not a suitable primary key, we can generate one by using a database sequence in Oracle, or if you are using Microsoft SQL Server you can use an identity column. These values are usually just a number starting at 1, and each time we insert a row into the table the value is incremented. Primary keys are also important to allow us to set up referential integrity between tables, which we will discuss later.
To create a table, most databases come with a graphical user interface tool. While this is sufficient in some cases, it will help you to learn Structured Query Language, more commonly known as SQL. SQL is the programming language we use to interact with the database (I'll be covering SQL in more detail in another article). You can also create tables with SQL which is the approach many coders use.
Let's create our very first database table! First, we will need to log into SQL*Plus, Oracle's command line utility for interacting with the database. Assuming you used 'oracle' for your password, bring up a command prompt and just type 'sqlplus system/oracle' at the prompt (this assumes the oracle bin directory was added to your path, which the installation should have done for you automatically; if it didn't you should add the bin directory manually). We'll create a new Oracle user, which will be the owner of the tables we are going to create, and we will call this user topcoder. The password to our topcoder user will be topcoder also. We will need to set our topcoder user up with some basic rights and assign it a default tablespace so it can have a place to store its tables. From the SQL*Plus command line, run the following SQL code:
Connected to: Oracle Database 10g Express Edition Release 10.2.0.1.0 - Production SQL> create user topcoder identified by topcoder; User created. SQL> alter user topcoder default tablespace users; User altered. SQL> grant connect to topcoder; Grant succeeded. SQL> alter user topcoder quota unlimited on users; User altered.
Now we're finally ready to create our coder table for the active algorithm coder list. The SQL code to run create our table is listed below. Note that in SQL*Plus, the command doesn't execute until you follow it with a semicolon -- you can type each line and press enter, and you don't have to worry about SQL*Plus trying to execute the command until you type a semicolon. There are some exceptions -- some commands, like running an external script, will execute without a semicolon -- but in most cases SQL*Plus won't do anything until you indicate the end of a command in this manner. (Also, please note that you won’t be required to type in the line numbers 2, 3, 4, etc. as shown below. Just type in the text and, each time you press return at the end of a line, the next line will begin with a line number to indicate that this text is a continuation of the previous line.)
SQL> create table topcoder.coder ( 2 coder_id number primary key 3 ,handle varchar2(20) 4 ,country_name varchar2(70) 5 ,alg_rating number 6 ,alg_vol number 7 ,alg_num_ratings number 8 ); Table created.
We have now created a database table. Notice that we specified coder_id as our primary key for the table. Now, to find out what data is in our table, we can use the SQL select statement. We will get into advanced types of queries in the later articles in this series, but for now just run the following code:
SQL> select * from topcoder.coder; no rows selected
Since we just created the table, there is not going to be any data in it, so let's insert a few records. We'll use the SQL insert statement to insert our records. Note the use of the 'commit' command after the insert statements. The commit command, as you probably guessed, tells the database to commit the changes to the table and make them permanent. If for some reason we don't want to keep these records we inserted, we can execute a 'rollback' command instead, assuming we haven't already committed yet. Here's the code:
SQL> insert into topcoder.coder 2 (coder_id,handle,country_name,alg_rating,alg_vol,alg_num_ratings) values 3 (123456,'slowpoke','United States',1020,320,42); 1 row created. SQL> insert into topcoder.coder 2 (coder_id,handle,country_name,alg_rating,alg_vol,alg_num_ratings) values 3 (123457,'fastcoder','China',1941,100,13); 1 row created. SQL> commit; Commit complete.
Now if we run our select statement again we will see that there is data in our table:
SQL> select * from topcoder.coder;
CODER_ID HANDLE
---------- --------------------
COUNTRY_NAME
----------------------------------------------------------------------
ALG_RATING ALG_VOL ALG_NUM_RATINGS
---------- ---------- ---------------
123456 slowpoke
United States
1020 320 42
123457 fastcoder
China
1941 100 13
If we now try to insert another record with the same primary key, watch what happens:
SQL> insert into topcoder.coder 2 (coder_id,handle,country_name,alg_rating,alg_vol,alg_num_ratings) values 3 (123456,'slowpoke','United States',1020,320,42); insert into topcoder.coder * ERROR at line 1: ORA-00001: unique constraint (TOPCODER.SYS_C004124) violated
This is why it is absolutely critical to use a primary key on each table. It ensures that you do not end up with duplicate records.
Go ahead and delete the records out of the coder table, since we will be loading this table with real data shortly. Oracle's truncate command is a quick way to clear out all the records in a table.
SQL> truncate table topcoder.coder; Table truncated.
Now let's go ahead and create the other tables we will be using throughout this article. Be sure to run the last command below, which will create the primary key on the round_results table.
SQL> create table topcoder.round_list ( 2 round_id number primary key 3 ,full_name varchar2(120) 4 ,short_name varchar2(50) 5 ,round_type_desc varchar2(100) 6 ,round_date date 7 ); Table created. SQL> SQL> create table topcoder.round_results ( 2 round_id number 3 ,coder_id number 4 ,room_id number 5 ,room_name varchar2(50) 6 ,paid number 7 ,old_rating number 8 ,new_rating number 9 ,new_vol number 10 ,num_ratings number 11 ,room_placed number 12 ,division_placed number 13 ,advanced varchar2(1) 14 ,challenge_points number 15 ,system_test_points number 16 ,defense_points number 17 ,submission_points number 18 ,final_points number 19 ,division varchar2(10) 20 ,problems_presented number 21 ,problems_submitted number 22 ,problems_correct number 23 ,problems_failed_by_system_test number 24 ,problems_failed_by_challenge number 25 ,problems_opened number 26 ,problems_left_open number 27 ,challenge_attempts_made number 28 ,challenges_made_successful number 29 ,challenges_made_failed number 30 ,challenge_attempts_received number 31 ,challenges_received_successful number 32 ,challenges_received_failed number 33 ,rated_flag varchar2(1) 34 ,level_one_submission_points number 35 ,level_one_final_points number 36 ,level_one_status varchar2(50) 37 ,level_one_time_elapsed number 38 ,level_one_placed number 39 ,level_one_language varchar2(50) 40 ,level_two_submission_points number 41 ,level_two_final_points number 42 ,level_two_status varchar2(50) 43 ,level_two_time_elapsed number 44 ,level_two_placed number 45 ,level_two_language varchar2(50) 46 ,level_three_submission_points number 47 ,level_three_final_points number 48 ,level_three_status varchar2(50) 49 ,level_three_time_elapsed number 50 ,level_three_placed number 51 ,level_three_language varchar2(50) 52 ); Table created. SQL> SQL> alter table topcoder.round_results add primary key (round_id,coder_id); Table altered.
IV. PL/SQL
PL/SQL is the language we use to write reusable Oracle code. The "PL" in PL/SQL stands for procedural language. In Oracle, you can store PL/SQL code in stored procedures, functions, and packages (packages consist of a specification and body). You can think of stored procedures and functions sort of like a single "method" in C++, JAVA, etc. where a stored procedure would have a return type of void. Packages, on the other hand, allow you to put multiple stored procedures and functions in a single compilation unit. As you might guess, it is extremely good coding practice to put your PL/SQL code in packages. For example, we might have a package called inventory_allocation, which contains the different stored procedures and functions used to allocate inventory to the different warehouses across a business. In the sections that follow, we will be creating a PL/SQL package to load some TopCoder RSS feeds into Oracle tables.
In the package specification, we can list our global variables, type declarations, constants, and any procedure and function declarations that we want external callers to be able to call in our package. In other words, if we have a procedure or function in our package body that isn't declared in the specification, then this procedure or function cannot be called by code outside of our package -- the procedure or function is essentially "private" to our package. PL/SQL also supports polymorphism, through which the same function or procedure name can be declared multiple times with different signatures (i.e. different parameters).
The coding conventions I use for PL/SQL are pretty simple, and based somewhat on the same ones Thomas Kyte (author of Expert Oracle and creator of asktom.oracle.com) uses. For parameters to procedures and functions I use a p_ prefix. For local procedure and function variables I use an l_ prefix. For global variables I use a g_ prefix. For type definitions I use a t_ prefix. And finally, for constants I use a c_ prefix. For procedure and function names I use underscores between key words (ex: load_coder_table). Since PL/SQL is not case sensitive, I use lowercase for everything.
V. Loading RSS data
Now let's go ahead and load some real data into our tables from the TopCoder RSS feeds. While there are many other ways to load an RSS feed into a relational database table, like using a high level language such as JAVA or C#, we will be using PL/SQL to perform the task. We need to do a little preliminary setup before we can load the RSS feed, though.
First, we will create the PL/SQL topcoder.rss_util package we will be using to load the tables. The script you need to run to create the package is here. Go ahead and copy this script text and save it to a file somewhere on your machine (I saved mine as create_rss_util_pkg.sql).
Next, you can run the script from SQL*Plus by using the 'at' sign ('@') and providing the path to the script (note that you do not need to put a semicolon after the end of the script name). In the example below, I saved the script to C:\temp\create_rss_util_pkg.sql, so modify the command below to point to wherever you saved the script (be sure to type in the set define off command, as that will prevent SQL*Plus from prompting you for a parameter) .
SQL> set define off SQL> @c:\temp\create_rss_util_pkg.sql Package created. Package body created.
The easiest way to load an RSS feed, assuming you don't run into firewall issues, is to just load it directly from the website to the Oracle table. That is the method we will be using. If you do have firewall issues then there are other methods you can use that require the use of an intermediate table, but that's beyond the scope of this article.
In the case of our active algorithm coder list, when processing the RSS feed we want to insert the coder record (if we don't already have it in our coder table). If we do already have the record in our coder table, we want to update it so we get the latest information for the coder (rating, etc.). If you take a look at the load_coder_tbl procedure from the rss_util package we just created, you will see that we are using Oracle's createuri command to connect directly to the website and extract the active algorithm coder records.
We are using a loop to iterate through each coder record, which allows us to determine whether to insert new coder records that we don't already have in our topcoder.coder table, or update records that already exist in the table. When we run this procedure for the first time, we won't have any records in our coder table so all the records will get loaded.
For the Oracle SQL experts out there who are wondering why I didn't use Oracle's merge command to load the coder table, I actually tried to do so. It turned out to be about a minute slower than the technique I ended up using, however, which was to manually check to see if the coder record existed to determine whether to insert or update.
A few more comments about this load_coder_table procedure:
- To parse the XML, we use Oracle's xmlsequence operator to break up each 'row' in the RSS feed so we can work with them as individual rows. We then cast that xmlsequence as a table so that we can scroll through the record set row by row, loading each individual record to our topcoder.coder table.
- The extractvalue Oracle function allows us to pull out the exact XML attribute we want from each row.
We are now ready to load the active algorithm RSS feed, so type the following code into SQL*Plus:
SQL> declare 2 begin 3 topcoder.rss_util.load_coder_tbl; 4 commit; 5 end; 6 / PL/SQL procedure successfully completed.
Note that the script may take a minute or two to run, so don’t be alarmed. Hopefully you got the "PL/SQL procedure successfully completed" message. If you got errors, chances are good you ran into firewall issues. To verify that the table was actually loaded with coder records, run this SQL:
SQL> select count(*) from topcoder.coder;
COUNT(*)
----------
5004
Your count will probably be different, but as long as it's not zero it means records were loaded. So now we have loaded our topcoder.coder table with active coders! If you want to pull your coder record (assuming you have competed in an algo competition in the last 6 months) run the following code and change 'dcp' to your own handle:
SQL> select * from topcoder.coder where handle='dcp';
CODER_ID HANDLE
---------- --------------------
COUNTRY_NAME
----------------------------------------------------------------------
ALG_RATING ALG_VOL ALG_NUM_RATINGS
---------- ---------- ---------------
21684580 dcp
United States
1069 306 35
There are many things you can do with this table. Would you like to know how many coders from Poland have a rating greater than or equal to 1500? Run this query:
SQL> select count(*) from topcoder.coder where country_name='Poland' and alg_rating >= 1500;
COUNT(*)
----------
76
This rss_util package also contains some other procedures, namely, load_round_list_tbl and load_round_results_tbl, which we can use to load the round_list and round_results tables respectively. The load_round_list_tbl works similarly to the load_coder_tbl, that is, it either inserts or updates records, which results in our round_list table containing the latest round list information. So when we run this procedure the first time, all round list records will be loaded:
SQL> declare 2 begin 3 topcoder.rss_util.load_round_list_tbl; 4 commit; 5 end; 6 / PL/SQL procedure successfully completed.
There are two versions of the load_round_results_tbl procedure in our topcoder.rss_util package. The first version takes the round date as a parameter and the second version takes a round id as a parameter (this is an example of polymorphism). The way the round results RSS feed is designed is that you have to pass in a round id. So let’s say for example, that we want to load the round results for SRM 342. First we need to determine the round_id for SRM 342. We can get that information from our round_list table we just loaded using the following query:
SQL> select round_id from topcoder.round_list where short_name = 'SRM 342';
ROUND_ID
----------
10666
Now that we know the round_id, we're ready to call our load_round_results_tbl procedure plugging in the 10666 (round_id) value as the parameter:
SQL> declare 2 begin 3 topcoder.rss_util.load_round_results_tbl(10666); 4 commit; 5 end; 6 / PL/SQL procedure successfully completed.
But instead of having to go through the trouble of looking up the round id, we can use the other version of this procedure, which allows us to pass in a round date. Since SRM 342 took place on March 14 th, 2007, we would call the procedure as follows:
SQL> declare
2 begin
3 topcoder.rss_util.load_round_results_tbl(to_date('20070314','YYYYMMDD'));
4 commit;
5 end;
6 /
PL/SQL procedure successfully completed.
If you look at the code for the load_round_results_tbl procedure, you will notice that we delete any existing round results data we have for the round before reloading it. This step enables us to reload the round data as many times as we would like, without having to worry about manually deleting the records since the procedure handles it for us. So in the case where the round data might change (due to cheaters being eliminated, etc.) you can just reload it by re-running the procedure.
Now we're really starting to get some traction. We have a lot of useful information at our fingertips. The TopCoder site does an outstanding job of supplying various statistics about a match. However, suppose you want to see a statistic that's not on the site? Well now you can! For example, in SRM 342, let's find out which countries won the money and order it by the amount of money in descending order.
SQL> select country_name
2 ,sum(r.paid)
3 from topcoder.round_results r
4 ,topcoder.round_list l
5 ,topcoder.coder c
6 where r.coder_id = c.coder_id
7 and r.round_id = l.round_id
8 and l.short_name = 'SRM 342'
9 group by country_name
10 having sum(r.paid) != 0
11 order by 2 desc
12 ;
COUNTRY_NAME
----------------------------------------------------------------------
SUM(R.PAID)
-----------
China
1407
United States
632
Russian Federation
581
.
. (results truncated for brevity)
.
26 rows selected.
If the SQL in that command looks confusing, don't worry. We'll be covering SQL in more depth in an upcoming article. Hopefully, though, you can see from this example the power you can leverage with SQL queries.
So now, whenever we want to load the latest SRM round information into our database, we can use the following steps:
- Run our load_coder_tbl procedure to get the latest coder information
- Run our load_round_list_tbl procedure to get the latest round_list records
- Run our load_round_results_tbl procedure and pass in the date of the SRM of interest.
Here's a complete example of how we could load the data for SRM 343 into our database:
SQL> declare
2 begin
3 topcoder.rss_util.load_coder_tbl;
4 topcoder.rss_util.load_round_list_tbl;
5 topcoder.rss_util.load_round_results_tbl(
6 to_date('20070322','YYYYMMDD'));
7 commit;
8 end;
9 /
PL/SQL procedure successfully completed.
Note that if multiple rounds take place on a given date, the above code will load the information for all of those rounds.
If you wanted to get really fancy, you could modify the topcoder.rss_util PL/SQL package and create your own procedure that would encapsulate all of these calls into a single procedure to simply load round information. I'll leave that as an exercise for the reader.
If you prefer a GUI interface for viewing your query results, Oracle Express Edition does provide one. If you’re running Windows, just go to Start->Programs->Oracle Database 10g Express Edition->Go To Database Home Page. Login with your system account, and you will be taken to a page where you can select an SQL dropdown menu to run an SQL command. This tool does a much nicer job than SQL*Plus of presenting query results in an easier-to-read format. Another free GUI tool you may want to check out is Oracle’s SQL Developer tool.
In Part 2, coming soon, we'll look at more key components of relational databases, including indexes, referential integrity, constraints, views, transactions, and triggers. Until then, enjoy exploring your new TopCoder competition database, and good luck!